Habe heute mal die Open Source Sprach KI von OpenAI ausprobiert. Dazu habe ich mal das Whisper-Mic Github Repository (https://github.com/mallorbc/whisper_mic) ausgecheckt und installiert.
Ich habe mich für dieses Repository entschieden, da es die Audio-Signale direkt vom Mikrofon aufnimmt und transkribiert. Die Installation unter Ubuntu ist denkbar einfach.
- Das GitHub Repository auschecken
git clone https://github.com/mallorbc/whisper_mic.git
cd whisper_mic/ - Eine neue Anaconda Umgebung erstellen und aktivieren:
conda create -n whisper-mic python=3.9
conda deactivate
conda activate whisper-mic - Installation der Requirements
sudo apt-get install ffmpeg
sudo apt install portaudio19-dev python3-pyaudio
pip install -r requirements.txt
Das war’s schon. Während der Installation wird schon einiges heruntergeladen, aber das Modell fehlt noch. Beim ersten Start wird das ausgewählte Modell geladen.
Folgende Modelle stehen zur Verfügung: [tiny|base|small|medium|large]

Das Modell kann neben englisch auch noch eine ganze Menge anderer Sprachen – darunter auch Deutsch und die Word Error Rate ist mit 4.5 beim Modell large-v2 sehr gut.
Leider scheitert meine System an dem large-v2 Modell, da ich nur über ein RTX 3080 mit 16GB verfüge (product: GA104M [GeForce RTX 3080 Mobile / Max-Q 8GB/16GB]).
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 26.00 MiB (GPU 0; 7.79 GiB total capacity; 6.80 GiB already allocated; 3.19 MiB free; 7.14 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONFWie es scheint, kann CUDA nur 8GB der 16GB nutzen. Habe ein wenig im Internet nachgelesen, aber auf die schnelle nichts hilfreiches gefunden. CharGPT versucht es so zu erklären. Pech – ca. 2GB zu wenig VRAM ….

Kann leider nicht beurteilen, ob das so weit korrekt ist, auch wenn die Erklärung gar nicht so schlecht klingt ….
Ich nehme einfach das „medium“ Modell und schon reichen die 8GB aus.
python mic.py --model medium --verboseDer Fernseher läuft und das Modell scheint immer mal wieder etwas zu erkennen, aber das was das Modell erkennt ergibt keinen Sinn. Der Film ist auf deutsch und es wird immer wieder „Thanks for watching!“ erkannt. Aber der Fernseher ist etwas weiter weg und das Mikrofon von meinem Notebook ist evtl. nicht so gut.
Say something!
{'text': ' Thanks for watching!', 'segments': [{'id': 0, 'seek': 0, 'start': 0.0, 'end': 2.0, 'text': ' Thanks for watching!', 'tokens': [50364, 2561, 337, 1976, 0, 50464], 'temperature': 0.0, 'avg_logprob': -0.7786427906581334, 'compression_ratio': 0.7142857142857143, 'no_speech_prob': 0.857048749923706}], 'language': 'en'}
{'text': ' Thanks for watching!', 'segments': [{'id': 0, 'seek': 0, 'start': 0.0, 'end': 2.0, 'text': ' Thanks for watching!', 'tokens': [50364, 2561, 337, 1976, 0, 50464], 'temperature': 0.0, 'avg_logprob': -0.7688871792384556, 'compression_ratio': 0.7142857142857143, 'no_speech_prob': 0.9214887619018555}], 'language': 'en'}
{'text': ' Thanks for watching!', 'segments': [{'id': 0, 'seek': 0, 'start': 0.0, 'end': 2.0, 'text': ' Thanks for watching!', 'tokens': [50364, 2561, 337, 1976, 0, 50464], 'temperature': 0.0, 'avg_logprob': -0.8672780309404645, 'compression_ratio': 0.7142857142857143, 'no_speech_prob': 0.9193243980407715}], 'language': 'en'}Ich lese also folgenden Text vor:
Whisper ist ein universell einsetzbares Spracherkennungsmodell.
Es wurde auf einem großen Datensatz mit unterschiedlichen Audiodaten trainiert und ist ein Multitasking-Modell, das sowohl mehrsprachige Spracherkennung als auch Sprachübersetzung und Sprachidentifikation durchführen kann.
Das Ergebnis sieht dann wie folgt aus:
Say something!
{'text': ' sehr einsetzbare Sprache.', 'segments': [{'id': 0, 'seek': 0, 'start': 0.0, 'end': 3.36, 'text': ' sehr einsetzbare Sprache.', 'tokens': [50364, 5499, 21889, 10074, 30682, 7702, 6000, 13, 50532], 'temperature': 0.0, 'avg_logprob': -0.6086562156677247, 'compression_ratio': 0.7575757575757576, 'no_speech_prob': 0.7562025785446167}], 'language': 'de'}
{'text': ' Es wurde auf einem großen Datensitz mit unterschiedlichen Audiodaten trainiert.', 'segments': [{'id': 0, 'seek': 0, 'start': 0.0, 'end': 3.64, 'text': ' Es wurde auf einem großen Datensitz mit unterschiedlichen Audiodaten trainiert.', 'tokens': [50364, 2313, 11191, 2501, 6827, 23076, 9315, 694, 6862, 2194, 30058, 10193, 28943, 378, 7186, 3847, 4859, 13, 50546], 'temperature': 0.0, 'avg_logprob': -0.21618707180023194, 'compression_ratio': 0.9876543209876543, 'no_speech_prob': 0.600564181804657}], 'language': 'de'}
{'text': ' und ist ein Multitasking-Modell, das sowohl mehrsprachige Spracherkennung als auch Sprache', 'segments': [{'id': 0, 'seek': 0, 'start': 0.0, 'end': 4.48, 'text': ' und ist ein Multitasking-Modell, das sowohl mehrsprachige Spracherkennung als auch Sprache', 'tokens': [50364, 674, 1418, 1343, 14665, 270, 47211, 12, 44, 378, 898, 11, 1482, 19766, 12768, 5417, 18193, 608, 3969, 7702, 4062, 74, 1857, 1063, 3907, 2168, 7702, 6000, 50588], 'temperature': 0.0, 'avg_logprob': -0.23948976198832195, 'compression_ratio': 1.1111111111111112, 'no_speech_prob': 0.20455828309059143}], 'language': 'de'}
{'text': ' und Sprachidentifikation durchführen kann.', 'segments': [{'id': 0, 'seek': 0, 'start': 0.0, 'end': 4.28, 'text': ' und Sprachidentifikation durchführen kann.', 'tokens': [50364, 674, 7702, 608, 1078, 45475, 399, 7131, 69, 29540, 4028, 13, 50578], 'temperature': 0.0, 'avg_logprob': -0.25294458866119385, 'compression_ratio': 0.8431372549019608, 'no_speech_prob': 0.08213946968317032}], 'language': 'de'}
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.{'text': ' Thanks for watching!', 'segments': [{'id': 0, 'seek': 0, 'start': 0.0, 'end': 2.0, 'text': ' Thanks for watching!', 'tokens': [50364, 2561, 337, 1976, 0, 50464], 'temperature': 0.2, 'avg_logprob': -0.8731996672494071, 'compression_ratio': 0.7142857142857143, 'no_speech_prob': 0.8974059224128723}], 'language': 'en'}
Hinweis: Die ganzen Meta-Daten kann man unterdrücken, wenn man das Programm ohne „verbose“ startet.
Neben den ganzen Meta-Daten wird auch einiges vom Text erkannt und sogar noch übersetzt. Interessant ist, das die Übersetzung mehr Text enthält als der ursprünglich erkannte Text. Der Anfang fehlt komplett und auch sonst ist es nicht perfekt – aber trotzdem schon ganz gut.
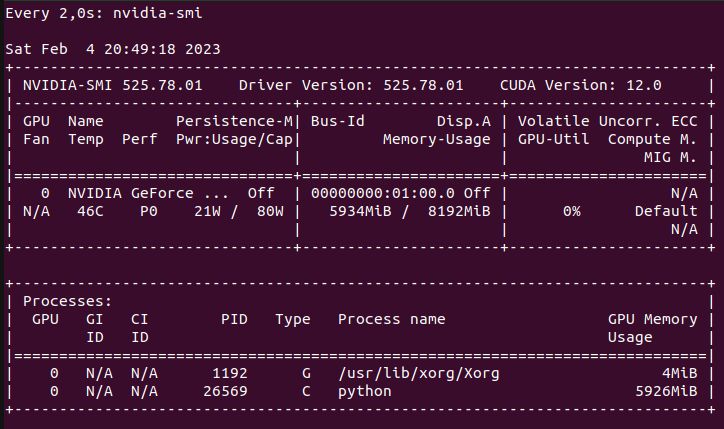
Auf meiner RTX 3080 werden knapp 6GB Speicher von verfügbaren 8BG verwendet. Weitere Tests zeigen ein ähnliches Ergebnis und ich werde es wohl noch mal mit einem anderen Mikrofon ausprobieren und wieder berichten.
PS: Das Paper zu dem Modell kann man unter https://arxiv.org/abs/2212.04356 nachlesen.
