Auf dem Jetson Orin Developer Kit muss man unter Umständen PyTorch aus den Sourcen installieren. Es gibt zwar entsprechende whl Dateien unter https://developer.download.nvidia.com/compute/redist/jp/v60/pytorch/ zum Download, aber die sind nicht mehr aktuell und es fehlen auch die torch.distribute Teile, die man unter Umständen auch benötigt – schade.
PyTorch Paket bauen
Die Installation startet mit dem Download der Sourcen mit den Befehlen:
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch
git checkout v2.5.1
git submodule sync
git submodule update --init --recursiveDamit wird das Repository geklont, die gewünschte Version ausgewählt und die Submodule initialisiert. Das dauert eine Zeit, da pytorch sehr umfangreich ist.
Als nächstes werden die CUDA Pfade manuell zu den Umgebungsvariablen gesetzt:
export PATH=/usr/local/cuda-12.2/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64:$LD_LIBRARY_PATHDiese Pfade können abweichend sein, aber bei der Standard-Installation des Jetson Orin mit dem Jetpack 6 sollte das so passen.
Damit pytorch gebaut werden kann, müssen noch eine Reihe von anderen Python Paketen installiert werden. Das kann mit dem folgenden Befehl durchgeführt werden.
pip install -r requirements.txtDamit werden bei pytorch 2.5.1 folgende Pakete nachinstalliert.
# Python dependencies required for development
astunparse
expecttest>=0.2.1
hypothesis
numpy
psutil
pyyaml
requests
# Setuptools>=74.0.0 stopped support for directly using private funcs(_msvccompiler)
# and consolidated all compiler logic in distutils used in Pytorch build, so older
# is required until pytorch build not refactored to work for latest setuptools.
setuptools<=72.1.0
types-dataclasses
typing-extensions>=4.8.0
sympy==1.12.1 ; python_version == "3.8"
sympy==1.13.1 ; python_version >= "3.9"
filelock
networkx
jinja2
fsspec
lintrunner
ninja
packaging
optree>=0.12.0 ; python_version <= "3.12"
Um pytorch mit CUDA Support zu installieren müssen ein paar Umgebungsvariablen gesetzt werden.
export USE_CUDA=1
export TORCH_CUDA_ARCH_LIST="8.7" # Je nach GPU-Architektur
export BUILD_TEST=OFF
export MAX_JOBS=6
export USE_NCCL=OK # NVIDIA Collective Communication Library bauen
export USE_DISTRIBUTED=1 # Wichtig, wenn man torch.distributed benötigt
export USE_QNNPACK=ON # ???
export USE_PYTORCH_QNNPACK=ON # ???
export PYTORCH_BUILD_VERSION=2.5.1
export PYTORCH_BUILD_NUMBER=1
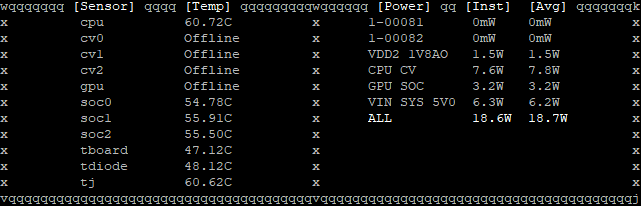
export USE_PRIORITIZED_TEXT_FOR_LD=1Der Wert für TORCH_CUDA_ARCH_LIST ist abhängig von der GPU Architektur und der L4T Version. Die Installierte Version kann man aber ganz einfach mit dem Befehl „jtop“ herausbekommen. Einfach jtop ausführen und checken, was oben in der ersten Zeile steht.

In meinem Fall ist das L4T 36.3.0 (Jetpack 6.0). Hier eine kleine Liste der korrekten Werte für TORCH_CUDA_ARCH_LIST abhängig von L4T/Jetpack
| L4T_VERSION.major >= 36 | JetPack 6 | TORCH_CUDA_ARCH_LIST=“8.7″ |
| L4T_VERSION.major >= 34 | JetPack 5 | TORCH_CUDA_ARCH_LIST=“7.2;8.7″ |
| L4T_VERSION.major == 32 | JetPack 4 | TORCH_CUDA_ARCH_LIST=“5.3;6.2;7.2″ |
Die Daten der Tabelle habe ich dem Script https://github.com/dusty-nv/jetson-containers/blob/master/jetson_containers/l4t_version.py von Dustin Franklin (dusty-nv) entnommen. Ein NVIDIA Jetson Developer der auch ein paar interessante Youtube Videos gemacht hat. Z.B. „https://www.youtube.com/watch?v=8Eu6zG0eEGY„
Nun kann das pytorch Build-Skript ausgeführt werden.
python setup.py installNun heißt es warten, denn auch wenn der Jetson Orin eine echte Maschine ist, braucht es doch seine Zeit, bis pytorch fertig gebaut ist. Man kann den Build Prozess noch etwas beschleunigen, indem man MAX_JOBS=8 setzt. In dem Fall sind dann alle 8 CPU Kerne ausgelastet und man kann in der Zwischenzeit mit dem Jetson Orin nicht mehr arbeiten – daher habe ich das nur auf 6 gestellt.
Mit USE_PRIORITIZED_TEXT_FOR_LD=1 verhindert man die Warnung „WARNING: we strongly recommend enabling linker script optimization for ARM + CUDA. To do so please export USE_PRIORITIZED_TEXT_FOR_LD=1“ und aktiviert eine Optimierung des Linkers, die den Build-Prozess beschleunigt und eine bessere Performance und optimierten Code auf dem Jetson Orin (ARM Architektur) erzeugt-
Hinweis: Mit den beiden Build-Flags DEBUG=1 und DEBUG_CUDA=1 kann man beim Kompilieren von PyTorch zusätzliche Debug-Funktionen aktivieren. Mit DEBUG=1 kann man das Debuggen mit gdb erleichtern und mit DEBUG_CUDA=1 aktiviert man spezifische Debug-Informationen für CUDA-Operationen und GPU-Berechnungen. Ich brauche das nicht, da ich vermutlich nicht ansatzweise fähig bin pytorch zu debuggen.
Das Bauen benötigt ca. 3 Stunden und der Energieverbrauch ist etwa 20W. D.h. ein pytorch build auf dem Jetson Orin Developer Kit benötigt etwa 60Wh und die Temperatur bewegt sich so um die 60°C. So energieeffizient kann man das wohl kaum auf einer anderen Hardware bauen. Jedenfalls noch nicht. Ich bin gespannt, auf The World’s Smallest AI Supercomputer: NVIDIA Project DIGITS und was damit möglich ist. Freue mich schon darauf, einen in die Finger zu bekommen 🙂
Wenn pytorch dann endlich fertig gebaut und installiert ist, kann man mit felgendem Python script überprüfen, ob PyTorch korrekt installiert wurde und CUDA unterstützt:
import torch
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0))Wenn alles korrekt funktionier hat, sollte die Ausgabe des Python Scripts wie folgt aussehen:
2.5.1
True
Orintorchaudio bauen
Wenn man schon mal dabei ist, kann man auch gleich torchaudio und torchvision bauen. Also los:
torchaudio auschecken:
git clone --recursive https://github.com/pytorch/audio
cd audio
git checkout v2.5.1
git submodule sync
git submodule update --init --recursiveAbhängigkeiten installieren. Im meinem Fall wird nur kaldi_io-0.9.8 installiert. Alle anderen Abhängigkeiten sind schon da.
pip install -r requirements.txtUmgebungsvariablen sind vermutlich noch gesetzt. Da muss also nichts mehr gemacht werden. Also kann man direkt den Build-Prozess starten.
python setup.py installDas bauen geht deutlich schneller und ist nach wenigen Minuten fertig. Mit folgendem kleinen Python Skript kann man prüfen, ob alles erfolgreich gebaut und installiert ist.
import torchaudio
print(torchaudio.__version__)Die Ausgabe sieh dann wie folgt aus:
2.5.1a0+1661daftorchvision bauen
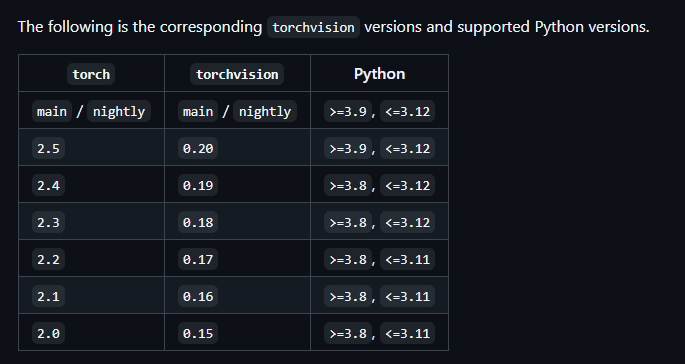
Fehlt noch torchvision. Laut der Tabelle unter https://github.com/pytorch/vision/ gehört torchvision==0.20 zu torch==2.5. Ich nehme aber 0.20.1. Neuer muss auch besser sein :-).
Also wieder von vorne: Auschecken, Umgebungsvariablen checken/setzen und Setup durchführen.
git clone --recursive https://github.com/pytorch/vision
cd vision
git checkout v0.20.1
# ... Umgebungsvariablen checken
git submodule sync
git submodule update --init --recursive
python setup.py installNach ein paar Minuten ist auch torchvision installiert und man kann mit dem folgenden Python Skript checken, ob es auch korrekt funktioniert.
import torchvision
print(torchvision.__version__)Die Ausgabe sollte wie folgt aussehen:
0.20.1a0+3ac97aaFazit
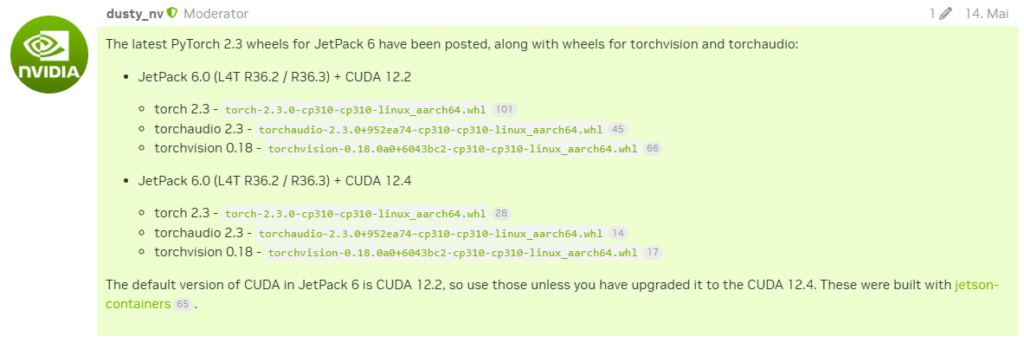
Der Aufwand pytorch auf dem Jetson Orin selbst zu bauen ist doch recht hoch und man sollte es nur machen, wenn es wirklich nötig ist. Ältere, vorkompilierte Versionen kann man auch unter https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048 finden. Diese Versionen sind von dusty_nv. Leider ist momentan die letzte Version torch 2.3, torchaudio 2.3 und torchvision 0.18 jeweils für JetPack 6.0 (L4T R36.2 / R36.3) + CUDA 12.2 und JetPack 6.0 (L4T R36.2 / R36.3) + CUDA 12.4 compiliert.