
Retrieval-Augmented Generation (RAG) ist eine leistungsstarke Technik, um generative KI-Modelle mit externem Wissen zu erweitern. Doch während RAG häufig für natürlichsprachige Dokumente verwendet wird, stellt die Anwendung auf Source Code eine besondere Herausforderung dar. Eine der zentralen Fragen dabei ist: Welches Embedding-Modell eignet sich am besten für die Vektorisierung von Java-Code?
Hier vergleiche ich 6 verschiedene Embedding-Modelle hinsichtlich ihrer Fähigkeit, relevante Code-Snippets effizient zu finden und für ein RAG-System bereitzustellen. Für den Test habe ich meinen Datensatz „Michael22/javadoc“ verwendet.
Ziel ist es, herauszufinden, welches Modell die beste Retrieval-Qualität liefert.
- Für den Test habe ich 1000 zufällige Einträge aus dem Datensatz verwendet und den jeweiligen Java-Code mit dem Embedding-Modell in einen Vektor umgewandelt und ein einer Qdrant Vektordatenbank gespeichert.
- Für das Retrieval habe ich die zugehörigen JavaDoc Doku zu der Methode mit dem gleichen Embedding-Modell in einen Vektor umgewandelt und in der Qdrant eine Cosine-Similarity-Search durchgerührt und die Top 10 Ergebnisse verglichen.
Ziel ist es herauszufinden, ob die Cosine-Similarity zwischen dem Java-Code und dem JavaDoc des Embedding-Modells ausreichend ist um den Source-Code anhand der JavaDoc in der Vektor-Datenbank zu finden.
Die Punkte habe ich nach Folgender Methode vergeben.
def calculate_value(x):
return 1 / (2 ** x)Daraus ergeben sich folgende Punkte, die für ein Retrieval vergeben werden.
Pos: 1 Value: 1.0
Pos: 2 Value: 0.5
Pos: 3 Value: 0.25
Pos: 4 Value: 0.125
Pos: 5 Value: 0.0625
Pos: 6 Value: 0.03125
Pos: 7 Value: 0.015625
Pos: 8 Value: 0.0078125
Pos: 9 Value: 0.00390625
Pos: 10 Value: 0.001953125
So ergibt sich eine maximale Punktzahl von 1000 Punkten für die 1000 Datensätze.
Für den Test habe ich 6 unterschiedliche Embedding Modelle verwendet, die alle einen im mteb/leaderboard relativ weit oben gelistet sind und eine Größe von 7B haben. Zusätzlich habe ich das Qodo/Qodo-Embed-1-7B Modell verwendet, das nicht im mteb/leaderboard gelistet ist, aber laut Qodo Ltd. besonders gut für Retrieval Aufgaben der Programmiersprachen Python, C++, C#, Go, Java, Javascript, PHP, Ruby und Typescript geeignet ist.
Qodo-Embed-1 ist ein hochmodernes Code-Embedding Modell, das für Retrieval-Aufgaben im Bereich der Softwareentwicklung entwickelt wurde. Es wird in zwei Größen angeboten: lite (1,5B) und medium (7B). Das Modell ist für die Abfrage von natürlicher Sprache zu Code und von Code zu Code optimiert, was es für Anwendungen wie Codesuche, Retrieval-Augmented-Generierung (RAG) und kontextuelles Verständnis von Programmiersprachen sehr effektiv macht.
Quelle: https://huggingface.co/Qodo/Qodo-Embed-1-7B
Folgende 6 Modelle habe ich ausgewählt:
| Name | Datum | Anzahl Parameter | Embedding-Dimension |
| Qodo/Qodo-Embed-1-7B | 24.02.2025 | 7.07B | 3584 |
| Alibaba-NLP/gte-Qwen2-7B-instruct | 16.06.2024 | 7.61B | 3584 |
| Linq-AI-Research/Linq-Embed-Mistral | 29.05.2024 | 7.11B | 4096 |
| Haon-Chen/speed-embedding-7b-instruct | 01.11.2024 | 7.11B | 4096 |
| Salesforce/SFR-Embedding-2_R | 14.06.2024 | 7.11B | 4096 |
| GritLM/GritLM-7B | 11.02.2024 | 7.24B | 4096 |
Den Python Code zum Ausführen Tests habe ich unter https://github.com/msoftware/JavaDoc-Embedding-Test zur Verfügung gestellt (So wie er ist, ist der Code nicht schön, aber wenn man die IP Adressen anpasst, funktioniert er 🙂 ). Es gibt pro Modell 2 Dateien eine die auf -create.py endet und eine die auf -test.py endet. Mit der ersten Datei erstellt man die Vektoren und speichert sie in der Datenbank und mit der -test.py Datei wird dann das Modell getestet.
Ich habe die Modelle auf einem Jetson Orin 64GB Developer Kit ausgeführt. Auf der Hardware ist die Ausführung nicht besonders schnell und das erstellen eines Embedding Vectors dauert je nach Modell und Größe des Java Codes ca. 3 Sekunden. Das Retrieval funktioniert deutlich schneller, obwohl meine Qdrant Datenbank nur auf einem alten Fujitsu PC Q556/2 Mini Intel i3-6100T 16GB RAM 256GB m.2 SSD läuft, den ich mal für 60€ bei Ebay gekauft habe.
Ergebnis
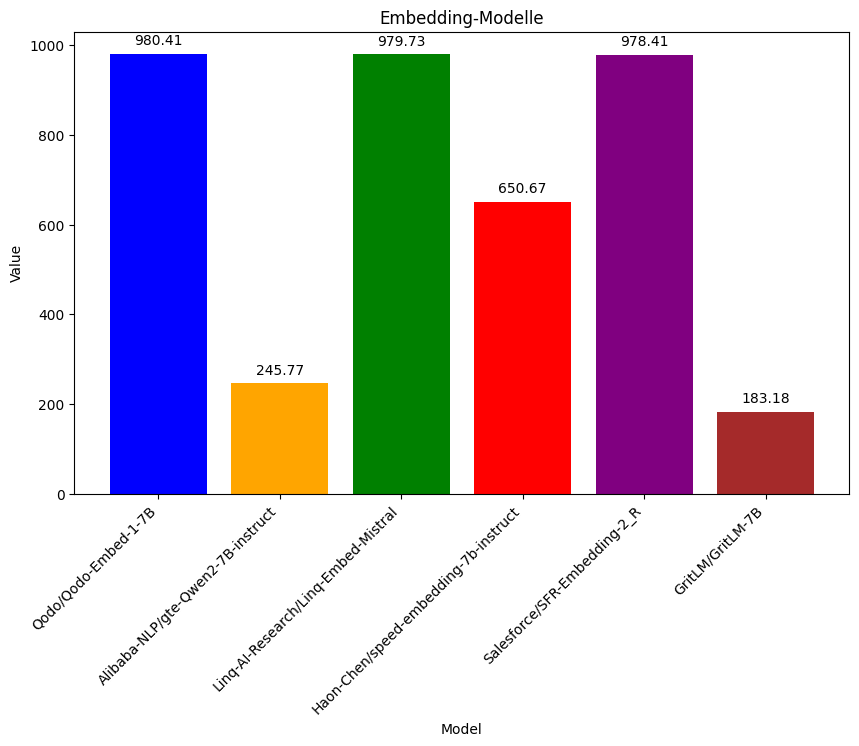
Die Punktzahlen im Balkendiagramm zeigen, dass Qodo/Qodo-Embed-1-7B, Linq-Embed-Mistral und Salesforce/SFR-Embedding-2_R mit fast identischen Werten (um 980) am besten abgeschnitten haben. Haon-Chen/speed-embedding-7b-instruct liegt mit ~650 Punkten im Mittelfeld. Alibaba-NLP/gte-Qwen2-7B-instruct (~246 Punkte) und GritLM-7B (~183 Punkte) haben deutlich schlechter performt.
Mögliche Erklärungen
Modelle wie Qodo und Linq-Embed-Mistral sind möglicherweise besser auf Code optimiert oder enthalten mehr Source-Code-Daten im Training. Die Unterschiede in der Dimensionalität (3584 vs. 4096) könnten auch Einfluss auf die Genauigkeit haben. Es ist auch möglich, dass sich manche Modelle stärker auf allgemeine NLP-Aufgaben fokussieren, während andere speziell für Embedding und Retrieval angepasst sind.
Fazit
Die Ergebnisse zeigen, dass nicht alle Embedding-Modelle gleichermaßen gut für die Vektorisierung und das Retrieval von Java-Code geeignet sind. Qodo/Qodo-Embed-1-1.5B, Linq-Embed-Mistral und Salesforce/SFR-Embedding-2_R liefern mit rund 980 Punkten die beste Retrieval-Qualität und konnten relevante Code-Snippets zuverlässig weit vorne in den Top-10-Ergebnissen platzieren.
Haon-Chen/speed-embedding-7b-instruct befindet sich mit etwa 650 Punkten im Mittelfeld, was darauf hindeutet, dass es brauchbare, aber nicht immer optimale Ergebnisse liefert. Die Modelle Alibaba-NLP/gte-Qwen2-7B-instruct und GritLM-7B zeigen mit unter 250 Punkten eine deutlich schwächere Leistung und sind daher für den Einsatz in einem Java-Code-RAG-System weniger geeignet.
Die Analyse zeigt sehr deutlich, wie wichtig es ist, Embedding-Modelle gezielt für den jeweiligen Anwendungsfall zu evaluieren. Auch wenn ein Modell im mteb/Leaderboard weit oben steht, bedeutet das nicht zwangsläufig, dass es für eine spezifische Retrieval Aufgabe optimal ist. Es ist wichtig, immer zu prüfen, ob das Embedding Model und die Aufgabe zueinander passen.