
Spoiler: Ja, das geht wirklich. Unsloth AI hat eine Version mit dynamischer 1,78-Bit-GGUFs Quantisierung veröffentlicht, die optimale Genauigkeit durch selektive Quantisierung der Schichten gewährleistet. Die Llama-4-Scout-17B-16E-Instruct-GGUF:IQ1_M Variante ist nur ca. 35GB groß und passt locker in den 64GB Speicher des Jetson Orin Developer Kit. Die 10.000.000 Kontextlänge wird man zwar vermutlich nicht nutzen können, da der KV Cache den VRAM sprengen würde, aber ich schätze mal eine Kontext Länge von 1.000.000 wird vermutlich machbar sein. Also direkt mal das Modell herunterladen und dann mal testen To be continued ….. 🙂
Kommentare sind geschlossenKategorie: Allgemein

LLMs sind mächtig und sie enthalten Unmengen an Informationen, aber es ist nicht immer leicht, diese Informationen herauszukitzeln, denn die Antworten sind immer nur so gut wie die Anweisungen, die dem Modell gegeben werden. Wenn man bessere, relevantere und nützlichere Antworten von KI-Tools wie ChatGPT, Mistral oder Anthropic erhalten möchte, dann ist Prompt Engineering der Schlüssel. Prompt Engineering ist im Wesentlichen die Kunst, KI-Modellen klare, präzise und effektive Anweisungen zu geben. Hier sind 4 einfache, aber wirkungsvolle Tipps, die man sofort anwenden kann. Einfachheit ist Trumpf Kontext mitgeben Was genau brauchst du? Schalte Expertenwissen frei Bonus Tipp – Kenne dein Modell! Jedes Modell – sei es GPT-4, Qwen, Llama oder ein anderes – wurde mit unterschiedlichen Daten trainiert und hat…
Kommentare sind geschlossen
Eine sehr spannende Technik zur Beschleunigung der Inferenz ist Speculative Decoding. Dabei wird ein kleines, schnelleres Modell genutzt, um Vorschläge zu generieren, die dann von einem größeren Modell überprüft und übernommen oder verworfen werden. In diesem Blogpost werde ich Speculative Decoding in llama.cpp genauer unter die Lupe nehmen und einen Performance-Vergleich mit und ohne diese Technik durchführen. Dabei kommt das leistungsstarke Qwen/Qwen2.5-Coder-32B-Instruct-Modell zum Einsatz, das für Code-Generierung optimiert ist. Der Fokus liegt auf den Auswirkungen von Speculative Decoding auf Geschwindigkeit und Antwortqualität. Ist die Technik ein echter Gamechanger oder nur eine nette Spielerei? Finden wir es heraus! Für den Test habe ich auf meinem Jetson Orin 64GB Developer Kit llama.cpp mit CUDA Support installiert und den llama.cpp Server einmal mit…
Kommentare sind geschlossen
Retrieval-Augmented Generation (RAG) ist eine leistungsstarke Technik, um generative KI-Modelle mit externem Wissen zu erweitern. Doch während RAG häufig für natürlichsprachige Dokumente verwendet wird, stellt die Anwendung auf Source Code eine besondere Herausforderung dar. Eine der zentralen Fragen dabei ist: Welches Embedding-Modell eignet sich am besten für die Vektorisierung von Java-Code? Hier vergleiche ich 6 verschiedene Embedding-Modelle hinsichtlich ihrer Fähigkeit, relevante Code-Snippets effizient zu finden und für ein RAG-System bereitzustellen. Für den Test habe ich meinen Datensatz „Michael22/javadoc“ verwendet. Ziel ist es, herauszufinden, welches Modell die beste Retrieval-Qualität liefert. Ziel ist es herauszufinden, ob die Cosine-Similarity zwischen dem Java-Code und dem JavaDoc des Embedding-Modells ausreichend ist um den Source-Code anhand der JavaDoc in der Vektor-Datenbank zu finden. Die Punkte habe…
Kommentare sind geschlossen
In diesem Test lasse ich das Sprachmodell Gemma 3 27B auf dem Jetson Orin 64GB laufen – mit Ollama und Open-WebUI als Interface. Ich prüfe Performance, Antwortgeschwindigkeit und mögliche Einsatzbereiche. Kann der Jetson Orin mit diesem großen Modell umgehen? Finde es in diesem Video heraus! 🚀💡
Kommentare sind geschlossen
Open-WebUI bietet eine benutzerfreundliche Möglichkeit sowohl lokale als auch nicht lokale LLMs dank der weit verbreiteten OpenAI API Schnittstelle in einer Web-Applikation zu verwenden. Doch es gibt Anbieter wie z.B. Anthropic, die nicht einfach so als OpenAI-API-Verbindung hinzugefügt werden können, da das API nicht 100% kompatibel mit der OpenAI API Schnittstelle ist. 🙁 Versucht man es trotzdem, bekommt man den Fehler: OpenAI: Network Problem Beispiel: Die Anthropic Modelle können per API mit folgendem Aufruf abgerufen werden: Das Ergebnis sieht dann wie folgt aus: So weit so gut, aber Open-WebUI senden den HTTP Header „anthropic-version: 2023-06-01“ nicht und dann sieht die Welt ganz anders aus. Ohne den „anthropic-version“ Header sieht das Ergebnis folgendermaßen aus. Schade, dass man nicht einfach einen zusätzlichen…
Kommentare sind geschlossen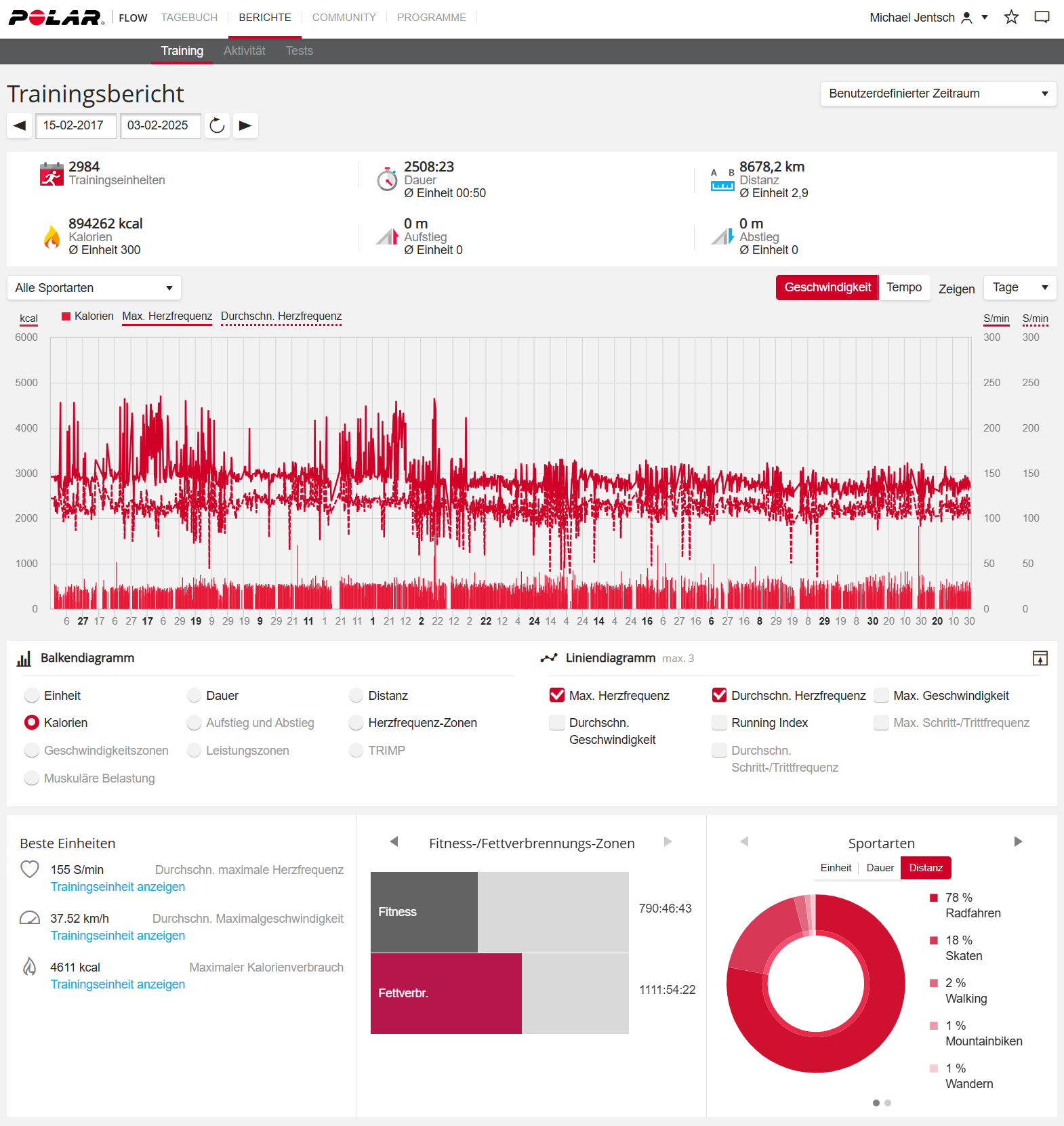
Ich habe folgenden Screenshot von meinem Trainingsbericht gemacht und verschiedenen Multimodalen Modellen 3 Fragen dazu gestellt. Ich habe in allen Fällen die kostenlose Version verwendet. Folgenden Prompt habe ich verwendet um die 3 Fragen zu stellen. Beantworte mir folgende 3 Fragen zu dem Trainingsbericht. 1. Basierend auf dem Trainingsverlauf. Wann sind 1.000.000 kcal erreicht? 2. Was fällt Dir an dem Diagramm der Herzfrequenz auf? 3. Wie viele Kilometer bin ich in der angegebenen Zeit auf dem Skateboard gefahren? Die korrekte Antwort auf ChatGPT Schon mal nicht schlecht. Alle drei Fragen sind erst mal gut beantwortet. Bei der ersten Frage hätte ich mir noch gewünscht, dass ChatGPT den Zeitraum berücksichtigt und dann einen Zeitpunkt in der Zukunft mitteilt. Bei der Zweiten…
Kommentare sind geschlossen
Für einen Test von deepseek-r1:70b in der Q4_K_M Variante habe ich mal eine SimpleBench Frage genommen und sie dem deepseek-r1:70b Modell in der Q4_K_M Variante gestellt. SimpleBench (simple-bench.com) ist ein Multiple-Choice-Text-Benchmark, der entwickelt wurde, um die Fähigkeiten von großen Sprachmodellen (LLMs) in Bereichen wie räumlich-zeitlichem Denken, sozialer Intelligenz und linguistischer Robustheit gegenüber sogenannten „Trickfragen“ zu evaluieren. Der Datensatz umfasst über 200 Fragen und ist öffentlich zugänglich. Er kann verwendet werden, um LLMs zu testen und deren Leistung mit bestehenden Modellen zu vergleichen. Ich habe mal die Frage 8 gewählt und auf deutsch übersetzt. SimpleBench Frage 8 (deutsche Übersetzung) In einem Regal stehen nur ein grüner Apfel, eine rote Birne und ein rosa Pfirsich. Das sind auch die jeweiligen Farben der…
Kommentare sind geschlossen
Ich habe auf YouTube folgendes Video gesehen und bin tatsächlich etwas irritiert. Das YouTube-Video mit dem Titel „12VHPWR on RTX 5090 is Extremely Concerning“ thematisiert die potenziellen Risiken des 12VHPWR-Stromanschlusses bei der NVIDIA RTX 5090 Grafikkarte. Es wird darauf hingewiesen, dass trotz der Verwendung von Drittanbieter-Kabeln solche Probleme bei früheren 6- oder 8-Pin-Anschlüssen nicht auftraten. Die Diskussion konzentriert sich auf die Besorgnis über mögliche Überhitzung oder Schmelzen der Anschlüsse, was auf Design- oder Herstellungsfehler hindeuten könnte. Die Community zeigt sich alarmiert über diese Entwicklungen und fordert weitere Untersuchungen, um die Sicherheit und Zuverlässigkeit der Hardware zu gewährleisten. Bei Zeitpunkt „16:40“ wird darauf hingewiesen, dass in der RTX 5090 Founders Edition die 6x12V Verbindungen zusammengeführt und zu einer 12V Spannungsquelle kombiniert…
Kommentare sind geschlossen
Neben dem Pretrainging und dem Post-Training ist RLHF eines der 3 wichtigsten Schritte beim Training von modernen LLMs. KI-Systemen werden hierbei aus menschlichem Feedback trainiert und an menschliche Werte und Präferenzen angepasst. In dem Buch „A Little Bit of Reinforcement Learning from Human Feedback“ kann man genau nachlesen, wie das im Detail funktioniert, was ein Reward Modell ist und wie genau die RLHF dem LLM den letzten Schliff gibt. Das Buch zielt darauf ab, eine Einführung in die Kernmethoden von RLHF für Personen mit einem oberflächlichen KI-Hintergrund zu geben. Aktuell ist das Buch noch nicht komplett fertig. Alle Teile die noch in Arbeit sind habe ich hier als „unvollständig“ gekennzeichnet. Alle Details, den Download des PDF und die Links zum…
Kommentare sind geschlossen