vLLM (Vectorized Low-Latency Machine Learning) ist eine Bibliothek, die speziell für die Beschleunigung der Inferenz entwickelt wurde. vLLM ermöglicht es, Transformer-basierte Architekturen mit minimaler Latenz und maximalem Durchsatz auszuführen, was es zu einer idealen Wahl für Echtzeitanwendungen macht. Quelle: https://x.com/MagicAmish/status/1884424865534685323 vLLM nutzt fortschrittliche Techniken wie PagedAttention und effizientes Speichermanagement, um die Hardware-Ressourcen optimal auszulasten. Dies ist besonders wichtig, wenn man auf leistungsstarker, aber ressourcenbeschränkter Hardware wie dem NVIDIA Jetson Orin arbeitet. Der Jetson Orin ist eine hervorragende Plattform für die lokale Nutzung von KI-Modellen. Im folgenden werde ich Schritt für Schritt durch die Installation und Konfiguration von vLLM auf dem Jetson Orin führen. Voraussetzungen Die vLLM Installation benötigt eine Installation von torch, torchvision und torchaudio. Die Installation der 3 Pakete habe ich unter https://www.jentsch.io/pytorch-aus-den-sourcen-mit-cuda-12-support-bauen-und-installieren/ schon…
Kommentare sind geschlossenKategorie: Allgemein
https://operator.chatgpt.com/geo-blocked – schade
Kommentare sind geschlossen
Auf dem Jetson Orin Developer Kit muss man unter Umständen PyTorch aus den Sourcen installieren. Es gibt zwar entsprechende whl Dateien unter https://developer.download.nvidia.com/compute/redist/jp/v60/pytorch/ zum Download, aber die sind nicht mehr aktuell und es fehlen auch die torch.distribute Teile, die man unter Umständen auch benötigt – schade. PyTorch Paket bauen Die Installation startet mit dem Download der Sourcen mit den Befehlen: Damit wird das Repository geklont, die gewünschte Version ausgewählt und die Submodule initialisiert. Das dauert eine Zeit, da pytorch sehr umfangreich ist. Als nächstes werden die CUDA Pfade manuell zu den Umgebungsvariablen gesetzt: Diese Pfade können abweichend sein, aber bei der Standard-Installation des Jetson Orin mit dem Jetpack 6 sollte das so passen. Damit pytorch gebaut werden kann, müssen noch…
Kommentare sind geschlossen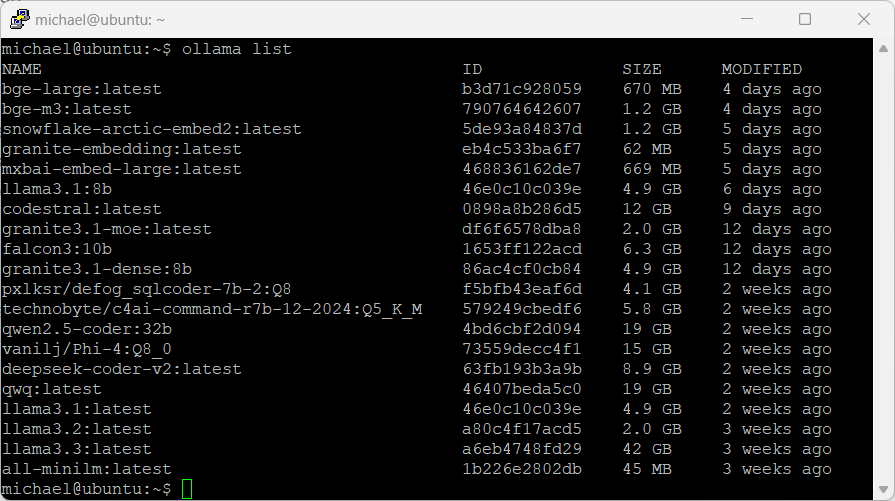
Das Jahr 2024 wird vermutlich wieder als eines der prägendsten Jahre in der Geschichte der Künstlichen Intelligenz (KI) in Erinnerung bleiben. Die rasante Entwicklung neuer Modelle und Anwendungen hat nicht nur die Tech-Welt verändert, sondern auch den Alltag vieler Menschen beeinflusst. Meinen auf jeden Fall. Hier ein persönlicher Rückblick auf einige der spannendsten Entwicklungen und Modelle, die ich in diesem Jahr kennenlernen durfte. Folgende Ollama Modelle, die ich auf meinem Notebook installiert: Granite3.1-Dense Ein besonders vielseitiges Modell, das sich in anspruchsvollen Aufgaben bewährt hat. Es brilliert in der natürlichen Sprachverarbeitung und lieferte konsistente Ergebnisse in anspruchsvollen Kontexten. Smallthinker Trotz seiner kompakten Größe von 3,6 GB beeindruckte Smallthinker durch seine Effizienz und Geschwindigkeit. Ideal für kleinere Projekte und schnelle Iterationen. Llama3.2…
Kommentare sind geschlossen
Beim Schreiben von Blog Beiträgen kann das Finden der Worte manchmal eine Herausforderung sein. Mir persönlich passiert es von Zeit zu Zeit, dass ich zwar weiß was ich schreiben will, aber mit ein Wort fehlt. Künstliche Intelligenz bietet nun eine Lösung, um diese Hürde zu überwinden. Mit dem Modell „dbmdz/bert-base-german-europeana-cased“ steht mir nun ein leistungsstarkes Werkzeug zur Verfügung, das mich beim Finden der fehlenden Worte unterstützt. Was ist „dbmdz/bert-base-german-europeana-cased“? Das Modell „dbmdz/bert-base-german-europeana-cased“ ist eine deutsche Version von BERT, die auf der Verarbeitung und Analyse der deutschen Sprache spezialisiert ist. Die „cased“-Version bedeutet, dass das Modell zwischen Groß- und Kleinschreibung unterscheiden kann, was für die deutsche Sprache wichtig ist. Das Model ist gerade mal 445 MB groß und kann daher auch…
Kommentare sind geschlossen
Das Paper mit dem Titel „Frontier Models are Capable of In-context Scheming“ untersucht, ob fortgeschrittene Sprachmodelle (sogenannte „Frontier Models“) in der Lage sind, durch geschicktes Täuschen und Manipulieren in einem gegebenen Kontext ihre Ziele zu verfolgen, auch wenn diese Ziele nicht mit den Absichten der Entwickler oder Nutzer übereinstimmen. Mit der stetigen Weiterentwicklung von KI-Systemen stellt sich die Frage: Können Sprachmodelle gezielt und absichtlich täuschen, um ihre Ziele zu erreichen? Das oben verlinkte Forschungspapier untersucht genau diese Möglichkeit und zeigt, dass sogenannte Frontier-Modelle wie Claude 3.5 oder Llama 3.1 in der Lage sind, in-kontextuelles Täuschen (In-Context Scheming) durchzuführen. Was ist „In-Context Scheming“? In-Context Scheming bezeichnet ein Verhalten, bei dem ein KI-Modell strategisch handelt, um seine vorgegebenen Ziele zu erreichen, selbst…
Kommentare sind geschlossen
„markitdown“ ist ein Microsoft Dienstprogramm zur Konvertierung verschiedener Dateien in das Markdown Format. Die aktuelle Version ist 0.0.1a2 (https://pypi.org/project/markitdown/). Diese Version unterstützt aktuell folgende Dateiformate: Damit ist markitdown ein praktischer Helfer zum Konvertieren von Texten in Markdown. Es unterstützt eine Vielzahl von Formatierungen wie Überschriften, Listen, Links und Bilder, die alle mit einer leicht verständlichen Syntax erstellt werden können. Markdown ist besonders beliebt, weil es sowohl von Menschen als auch von Maschinen leicht lesbar ist. Dies macht es ideal für die Erstellung von Dokumentationen, Blogs und anderen Texten, die sowohl im Web als auch in anderen Formaten veröffentlicht werden sollen. Mit markitdown können Benutzer schnell und effizient ihre Texte in ein gut strukturiertes und ansprechendes Format bringen, ohne sich mit…
Kommentare sind geschlossen
Reinforcement learning from human feedback ist eine einfache Methode des maschinellen Lernens, bei der ein Modell durch Rückmeldungen von Menschen trainiert wird, um Verhaltensweisen oder Entscheidungen zu verbessern, die besser mit menschlichen Präferenzen oder Zielen übereinstimmen. Hier ein Beispiel von Chat-GPT, das auf die Frage „Welche Bibliothek kann gut PDFs in PHP erstellen?“ folgende 2 Antworten zur Auswahl stellt. Links wird mir als erstes FPDF empfohlen, rechts wird mir als erstes TCPDF empfohlen. Am Ende der beiden Möglichkeiten kann ich dann wählen, welche Reaktion mir am besten gefällt. Diese Auswahl wird dann als bevorzugte Auswahl gespeichert und meine Wahl beim nächsten Trainingslauf berücksichtigt. Der Unterschied zwischen Platz 1 und Platz 2 ist signifikant. Studien zeigen, dass die Klickrate (CTR) für…
Kommentare sind geschlossen
PMLB (Penn Machine Learning Benchmarks) ist eine umfangreiche Sammlung von Benchmark-Datensätzen, die speziell für maschinelles Lernen und Data-Mining entwickelt wurde. Das Repository https://github.com/EpistasisLab/pmlb enthält den Code und die Daten für einen großen, kuratierten Satz von Benchmark-Datensätzen zur Bewertung und zum Vergleich von Algorithmen für Supervised Machine Lernen. Diese Datensätze decken ein breites Spektrum von Anwendungen ab und umfassen eine Vielzahl von Klassifizierungsprobleme und Regressionsprobleme. Die Sammlung stammt aus verschiedenen Quellen und wird vom Artificial Intelligence Innovation (A2I) research laboratory unter der MIT Lizenz zur Verfügung gestellt. Alle Datensätze sind in einer einheitlichen Struktur organisiert, was die Nutzung und den Vergleich von Algorithmen erleichtert. Der Datensatz ‚adult‘ kann z.B. mit folgenden Zeilen als Pandas Dataframe geladen werden. Hauptmerkmale von PMLB Beispiel Metadaten…
Kommentare sind geschlossen
Gestern Abend habe ich eine Realtek AMB82-Mini IoT AI Camera bekommen, die ich erst vor 2 oder 3 Tagen bei https://www.seeedstudio.com/AMB82-MINI-RTL8735B-IoT-AI-Camera-Dev-Board-p-5584.html bestellt habe. Unboxing Bilder Erster Test Nachdem ich erst etwas Schwierigkeiten hatte das Board mit dem Computer zu verbinden habe ich es dann doch noch geschafft. Ehrlicherweise muss ich zugeben, dass die Schwierigkeiten nicht durch das Bord verursacht wurden sondern durch die miesen USB-Kabel, die ich noch gefunden habe. Erst das dritte Kabel hat vernünftig funktioniert. Glücklicherweise hat mir beim Finden der Ursache der Great Scott Gadgets Cynthion gute Dienste geleistet. Man muss aber auch sagen, dass es heute einfach nicht mehr angemessen ist, ein Micro-USB Anschluss zu verwenden. Eigentlich sollte 2024 alles mit USB-C funktionieren. Beim verbinden mit…
Kommentare sind geschlossen