Beim Surfen bin ich auf ein mir bisher unbekanntes Huggingface Leaderboard aufmerksam geworden, dass sich speziell auf „Big Code Models“ konzentriert und die Leistung Multi-Language Code-Generierungsmodellen anhand des HumanEval und des MultiPL-E Benchmarks vergleicht.
https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard
Unter den Top-10 findet man die üblichen Verdächtigen.
- DeepSeek-Coder
- CodeLlama
- WizardCoder
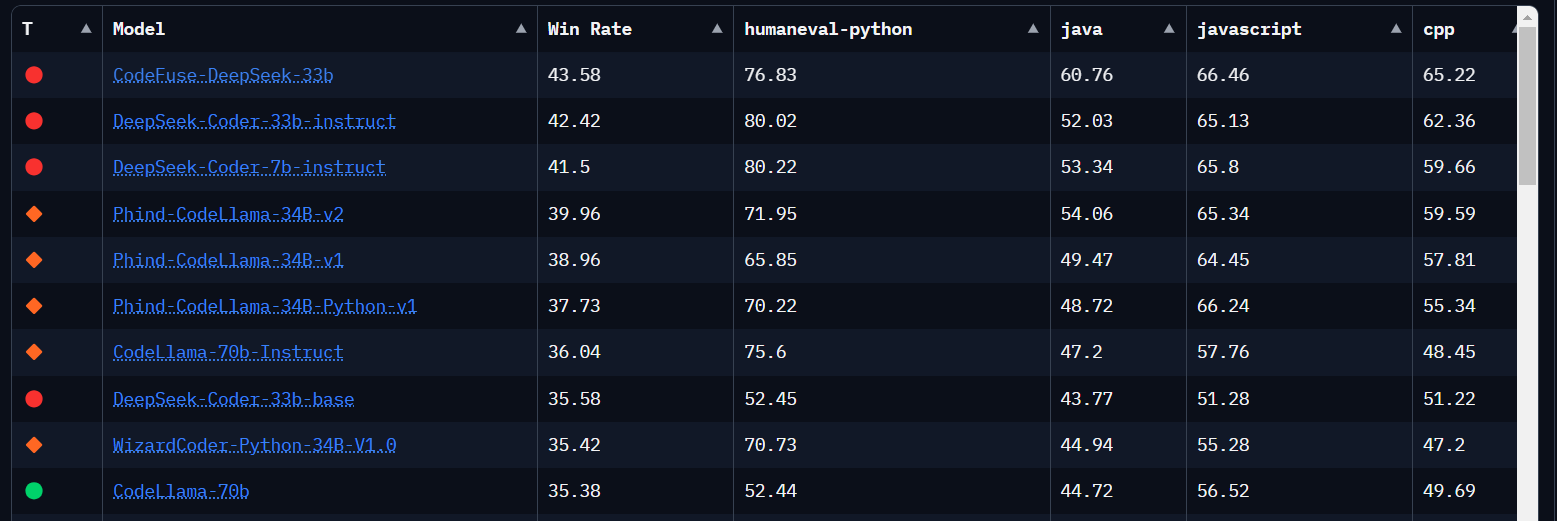
Aber auf Platz 1 steht CodeFuse-DeepSeek-33b. Davon habe ich bisher noch nichts gehört. Es erreicht 60.76 bei der Programmiersprache Java und übertrifft sogar DeepSeek-Coder-33b-instruct (52.03) und CodeLlama-70b (44.72).
Grund genug sich CodeFuse-DeepSeek-33b mal genauer anzusehen.
CodeFuse-DeepSeek-33b
Unter https://huggingface.co/codefuse-ai/CodeFuse-DeepSeek-33B-4bits kann man lesen, dass CodeFuse-DeepSeek-33B ein 33B Code-LLM ist, das mit Hilfe von QLoRA anhand mehrerer codebezogenen Aufgaben auf dem Basismodell DeepSeek-Coder-33B feingetunt wurde. Das klingt vielversprechend. Die DeepSeek-Coder Familie benutze ich schon relativ lange und habe gute Erfahrungen gemacht.
Auf der Webseite steht, dass es beim HumanEval(pass@1) Benchmark 78.65% erreicht. Es scheint aber trotzdem ein eher unbekanntes Model zu sein, da es gerade mal 47 Downloads hat.

Die Informationen auf der Webseite sehen auf den ersten Blick ganz gut aus und auch die Prompt-Templates sind hier mit angegeben.
Single-Round without System Prompt: """ <s>human User prompt... <s>bot """
Multi-Round with System Prompt: """ <s>system System instruction <s>human Human 1st round input <s>bot Bot 1st round output<|end▁of▁sentence|> <s>human Human 2nd round input <s>bot Bot 2nd round output<|end▁of▁sentence|> ... ... ... <s>human Human nth round input <s>bot """
Von dem Model gibt es auch eine 4Bit Variante, die auf meinen Jetson Orin 64 GB laufen sollte, …. die Vergleichstabelle zeigt, dass das 4bit model nur ca. 0.6% schlechter abschneidet als die Basis.
| Model | HumanEval(pass@1) | Date |
|---|---|---|
| CodeFuse-CodeLlama-34B | 74.4% | 2023.9 |
| CodeFuse-CodeLlama-34B-4bits | 73.8% | 2023.9 |
| WizardCoder-Python-34B-V1.0 | 73.2% | 2023.8 |
| GPT-4(zero-shot) | 67.0% | 2023.3 |
| PanGu-Coder2 15B | 61.6% | 2023.8 |
| CodeLlama-34b-Python | 53.7% | 2023.8 |
| CodeLlama-34b | 48.8% | 2023.8 |
| GPT-3.5(zero-shot) | 48.1% | 2022.11 |
| OctoCoder | 46.2% | 2023.8 |
| StarCoder-15B | 33.6% | 2023.5 |
| Qwen-14b | 32.3% | 2023.10 |
| CodeFuse-StarCoder-15B | 54.9% | 2023.9 |
| CodeFuse-QWen-14B | 48.78% | 2023.10 |
| CodeFuse-CodeGeeX2-6B | 45.12% | 2023.11 |
| CodeFuse-DeepSeek-33B | 78.65% | 2024.01 |
| CodeFuse-DeepSeek-33B-4bits | 78.05% | 2024.01 |
Ein Code Beispiel gibt es auch, dass aber bei mir so nicht funktioniert. Ich habe es wie folgt angepasst und dann lief es.
import os
import torch
import time
from transformers import AutoTokenizer
from auto_gptq import AutoGPTQForCausalLM
os.environ["TOKENIZERS_PARALLELISM"] = "false"
def load_model_tokenizer():
"""
Load model and tokenizer based on the given model name or local path of the downloaded model.
"""
tokenizer = AutoTokenizer.from_pretrained("codefuse-ai/CodeFuse-DeepSeek-33B-4bits",
trust_remote_code=True,
use_fast=False,
lagecy=False)
tokenizer.padding_side = "left"
model = AutoGPTQForCausalLM.from_quantized("codefuse-ai/CodeFuse-DeepSeek-33B-4bits",
inject_fused_attention=False,
inject_fused_mlp=False,
use_safetensors=True,
use_cuda_fp16=True,
disable_exllama=True,
disable_exllama2=False,
device_map='auto' # Support multi-gpus
)
return model, tokenizer
def inference(model, tokenizer, prompt):
"""
Uset the given model and tokenizer to generate an answer for the specified prompt.
"""
st = time.time()
prompt = prompt if prompt.endswith('\n') else f'{prompt}\n'
inputs = f"<s>human\n{prompt}<s>bot\n"
input_ids = tokenizer.encode(inputs,
return_tensors="pt",
padding=True,
add_special_tokens=False).to("cuda")
with torch.no_grad():
generated_ids = model.generate(
input_ids=input_ids,
top_p=0.95,
temperature=0.1,
do_sample=True,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id
)
print(f'generated tokens num is {len(generated_ids[0][input_ids.size(1):])}')
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(f'generate text is {outputs[0][len(inputs): ]}')
latency = time.time() - st
print('inference: {} seconds'.format(latency))
if __name__ == "__main__":
start_time = time.time()
prompt = 'Please write a QuickSort program in Python'
model, tokenizer = load_model_tokenizer()
inference(model, tokenizer, prompt)
run_time = time.time() - start_time
print('running: {} seconds'.format(run_time))
Den Download der 18GB Daten lasse ich einfach über Nacht laufen.
michael@orin:~/.cache/huggingface/hub/models--codefuse-ai--CodeFuse-DeepSeek-33B-4bits$ find . ./refs ./refs/main ./.no_exist ./.no_exist/959e280bfc045b4fab43dfd0d589d555e7193a9a ./.no_exist/959e280bfc045b4fab43dfd0d589d555e7193a9a/model.safetensors.index.json ./.no_exist/959e280bfc045b4fab43dfd0d589d555e7193a9a/pytorch_model.bin ./.no_exist/959e280bfc045b4fab43dfd0d589d555e7193a9a/tokenizer.model ./.no_exist/959e280bfc045b4fab43dfd0d589d555e7193a9a/added_tokens.json ./.no_exist/959e280bfc045b4fab43dfd0d589d555e7193a9a/model.safetensors ./.no_exist/959e280bfc045b4fab43dfd0d589d555e7193a9a/pytorch_model-00001-of-00007.bin ./.no_exist/959e280bfc045b4fab43dfd0d589d555e7193a9a/adapter_config.json ./snapshots ./snapshots/959e280bfc045b4fab43dfd0d589d555e7193a9a ./snapshots/959e280bfc045b4fab43dfd0d589d555e7193a9a/pytorch_model.bin.index.json ./snapshots/959e280bfc045b4fab43dfd0d589d555e7193a9a/tokenizer.json ./snapshots/959e280bfc045b4fab43dfd0d589d555e7193a9a/config.json ./snapshots/959e280bfc045b4fab43dfd0d589d555e7193a9a/gptq_model-4bit-64g.safetensors ./snapshots/959e280bfc045b4fab43dfd0d589d555e7193a9a/special_tokens_map.json ./snapshots/959e280bfc045b4fab43dfd0d589d555e7193a9a/tokenizer_config.json ./snapshots/959e280bfc045b4fab43dfd0d589d555e7193a9a/quantize_config.json ./blobs ./blobs/5ff8f57b46ed9d045d6a786cc8e89e79c0005742 ./blobs/0dfa4268afc2cf45515dec553772d7ca79f79762 ./blobs/340b041b4df26ed5685d5a8ad8654dccdac838c2 ./blobs/803bea49450fe24bc2c3a44ef36938ea248a10c780d1fa0003e5b92099e8dfaf ./blobs/5e56343af8d85823f6f0bf0953d3d988b7dadc4c ./blobs/65125b3a55e4f2adb51deaa4888697a3f8c19406 ./blobs/b8bdc767c2a42a55bb1699a8ec913faaf952997a michael@orin:~/.cache/huggingface/hub/models--codefuse-ai--CodeFuse-DeepSeek-33B-4bits$ michael@orin:~/.cache/huggingface/hub/models--codefuse-ai--CodeFuse-DeepSeek-33B-4bits$ du -sh . 18G .
CodeFuse-DeepSeek-33b Test
Ein erster Test soll für die Methode onDataAvailable der WsFrameServer Klasse aus dem Tomcat Repository ein JavaDoc erstellen. Dazu verwende ich folgenden Prompt.
Write a short and complete JavaDoc for the given Java method. Consider all parameters and return values Take in account all parameters and return values.
```java
private void onDataAvailable() throws IOException {
if (log.isDebugEnabled()) {
log.debug("wsFrameServer.onDataAvailable");
}
if (isOpen() && inputBuffer.hasRemaining() && !isSuspended()) {
// There might be a data that was left in the buffer when
// the read has been suspended.
// Consume this data before reading from the socket.
processInputBuffer();
}
while (isOpen() && !isSuspended()) {
// Fill up the input buffer with as much data as we can
inputBuffer.mark();
inputBuffer.position(inputBuffer.limit()).limit(inputBuffer.capacity());
int read = socketWrapper.read(false, inputBuffer);
inputBuffer.limit(inputBuffer.position()).reset();
// Some error conditions in NIO2 will trigger a return of zero and close the socket
if (read < 0 || socketWrapper.isClosed()) {
throw new EOFException();
} else if (read == 0) {
return;
}
if (log.isDebugEnabled()) {
log.debug(sm.getString("wsFrameServer.bytesRead", Integer.toString(read)));
}
processInputBuffer();
}
}
```
Das Ergebnis kann man hier bewundern – wenn man Geduld hat :-).
Nach fast 260 Sekunden (> 4 Min.) ist das Skript durchgelaufen. Davon fallen aber „nur“ ca. 70 Sekunden auf die reine Inference an. Den Rest der Zeit wird dafür verwendet, das Model und den Tokenizer von der Platte (M.2 SSD) zu laden.
Aber das Ergebnis ist OK. Das Model hat den Code „verstanden“ und eine gute Beschreibung erzeugt.

Die Performance des Jetson Orin ist natürlich unterirdisch. Das Model kann also auf der Hardware nicht als Code-Assistent genutzt werden. Da ist etwas mehr Power nötig.
Lizenz
A auf der Github Seite kann man nachlesen, dass CodeFuse unter der Apache 2.0 Lizenz veröffentlicht ist.

Im Huggingface Repository kann man auch die Datei MODEL_LICENSE.md finden, die etwas mehr Details liefert.
Fazit
Auf den ersten Blick scheint es ein gutes Model zu sein. Aber es ist noch zu früh, um ein Fazit zu ziehen, denn es ist auch möglich, dass es ein Model aus der Klasse „Pretraining on the Test Set Is All You Need“ ist. Ich werde mich weiter damit beschäftigen und meine Erkenntnisse hier posten.