
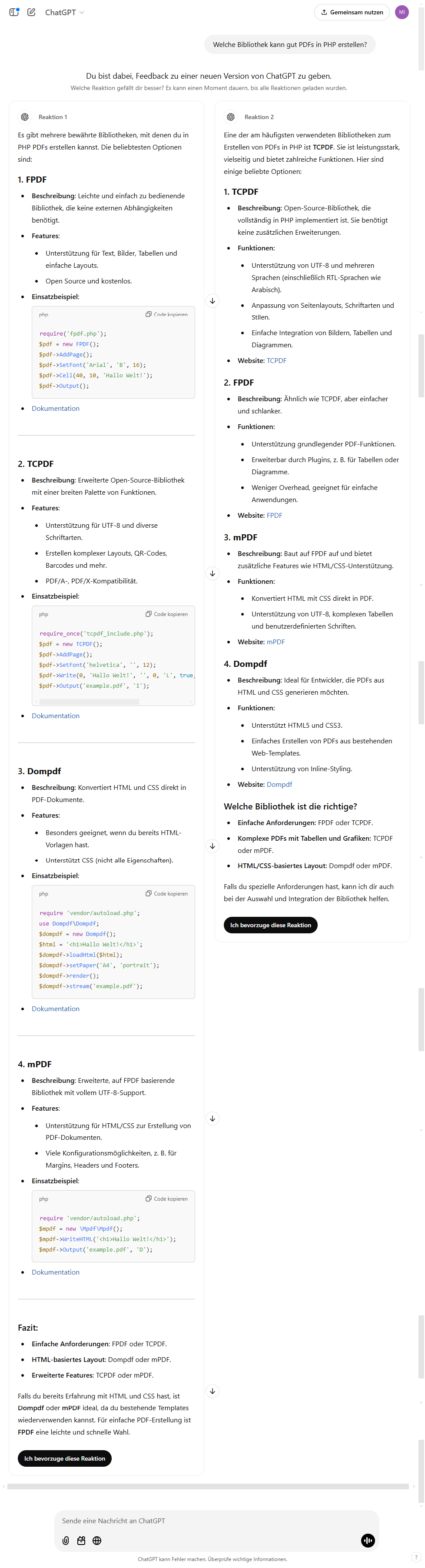
Reinforcement learning from human feedback ist eine einfache Methode des maschinellen Lernens, bei der ein Modell durch Rückmeldungen von Menschen trainiert wird, um Verhaltensweisen oder Entscheidungen zu verbessern, die besser mit menschlichen Präferenzen oder Zielen übereinstimmen. Hier ein Beispiel von Chat-GPT, das auf die Frage „Welche Bibliothek kann gut PDFs in PHP erstellen?“ folgende 2 Antworten zur Auswahl stellt.
Links wird mir als erstes FPDF empfohlen, rechts wird mir als erstes TCPDF empfohlen. Am Ende der beiden Möglichkeiten kann ich dann wählen, welche Reaktion mir am besten gefällt. Diese Auswahl wird dann als bevorzugte Auswahl gespeichert und meine Wahl beim nächsten Trainingslauf berücksichtigt.
Der Unterschied zwischen Platz 1 und Platz 2 ist signifikant. Studien zeigen, dass die Klickrate (CTR) für die erste Position oft deutlich höher ist als für die zweite. Laut verschiedenen Quellen liegt die CTR für Platz 1 bei etwa 30-40%, während Platz 2 nur noch etwa 15-20% der Klicks erhält. Der erste Platz hat also einen erheblichen Vorteil, sowohl in der Sichtbarkeit als auch in der Wahrscheinlichkeit, dass ein Nutzer auf das Ergebnis klickt. Dieser Unterschied wird durch die prominente Position und das größere Vertrauen, der ersten Ergebnisposition entgegenbringen, verstärkt. Der erste Platz ist somit entscheidend für den Erfolg in den organischen Suchergebnissen, da er in den meisten Fällen den größten Traffic anzieht. Ähnlich wird es auch bei den Antworten von Chat-GPT aussehen.
Meine Wahl
Gewählt habe ich FPDF. Zusätzlich habe ich noch ein Like hinterlassen, so dass ich nun hoffentlich einen Abdruck im nächsten Trainingslauf hinterlasse, den ich in der nächsten Version von Chat-GPT evtl. wiederfinden kann. So weit ist das nicht weiter kritisch, aber wenn sich vorstellt, dass statt FPDF und TCPDF dort nun Coca-Cola und Pepsi-Cola oder Nike und Adidas steht kann und sich eine Gruppe von „Hackern“ darauf einigt, einen der beiden zu boykottieren bzw. zu unterstützen, kann das einen sog. „Bias“ verursachen, der dazu führen kann, dass in Zukunft immer ein bestimmtes Produkt bevorzugt wird.
Fazit
Der Einfluss von Reinforcement learning from human feedback über die Chat-GPT Oberfläche kann zu Verzerrungen in den Ergebnissen und andere unfaire Auswirkungen haben, was ethische Bedenken und potenzielle negative Auswirkungen auf Produkte, Unternehmen oder Anwendungen nach sich zieht.
Bleibt nur zu Hoffen, dass ChatGPT nicht nur mein Feedback zu diesem Prompt berücksichtigt und meine Entscheidung darüber welche Reaktion ich bevorzuge gründlich hinterfragt. Allerdings bezweifle ich, dass mein Prompt „Welche Bibliothek kann gut PDFs in PHP erstellen?“ von vielen Menschen in ChatGPT eingegeben wird….