
Das neue Qwen3 bietet eine neue Flexibilität, wenn es darum geht, das Verhalten eines Modells gezielt zu steuern. Man kann mit einem einfachen Befehl Qwen3 in Ollama bzw. mit Open WebUI dazu bringt, „weniger zu denken“ – sprich, deterministischer oder direkter zu antworten.
Mit einem Wort im Prompt kann man explizit das „Thinking“ bei der Nutzung von Qwen3 deaktivieren, also quasi einen „No-Reasoning-Modus“ aktivieren. Das Ziel: Antworten ohne übermäßiges Reflektieren oder Ausschweifen – ideal für klare, schnelle Reaktionen etwa im technischen Support oder bei direkten API-Antworten.
Steuerung via „/think“ und „/nothink ist eine einfache, aber elegante Lösung. Man kann in der System- oder Benutzernachricht einfach die Steueranweisungen /think oder /nothink verwenden.
Beispiel:
System: /nothink
User: Gib mir die Top 5 Java-Frameworks für REST-APIs.
Damit wird Qwen3 angewiesen, ohne tiefere Gedankengänge oder Argumentationen zu antworten – ähnlich dem Deaktivieren von „enable_thinking“.
Wichtig: In mehrstufigen Konversationen zählt immer die letzte Anweisung. Wer also zwischen /think und /nothink wechselt, kann das Verhalten des Modells dynamisch anpassen.
Hier ein paar Screenshots von Qwen3 mit und ohne Thinking enabled
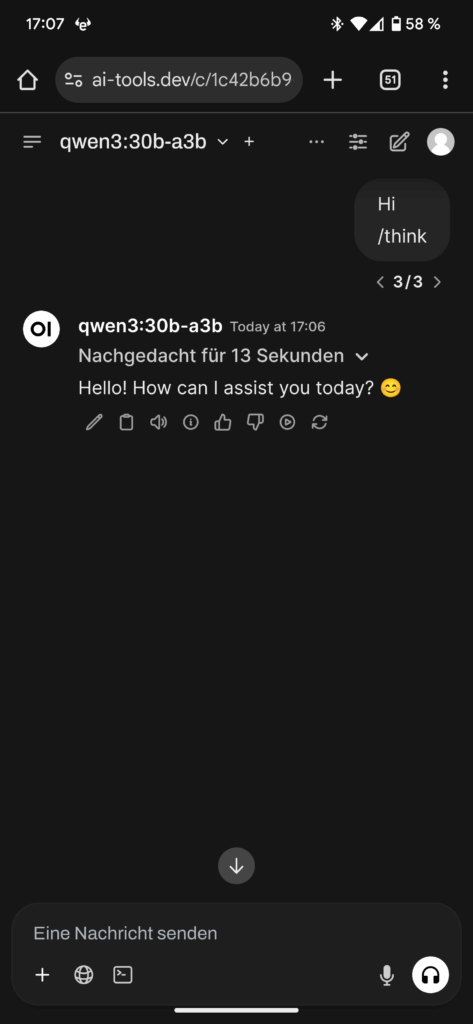
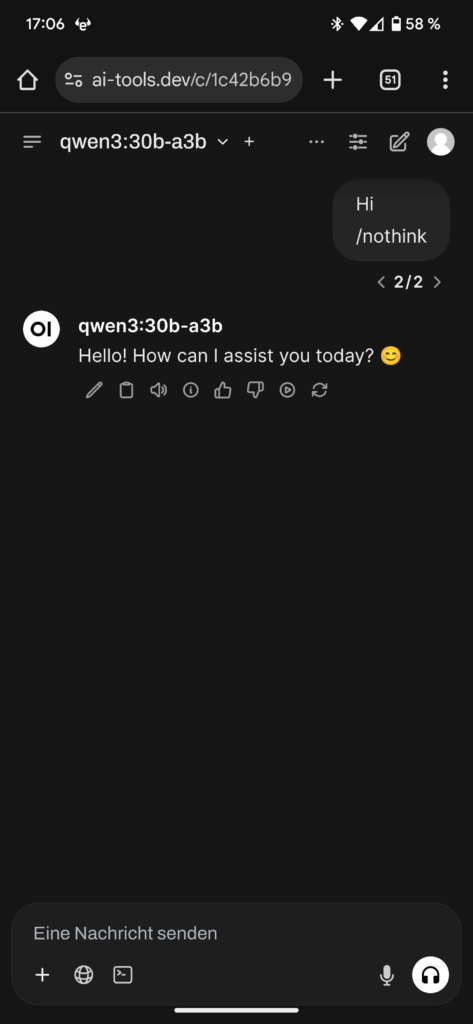
Meine ersten Experimente haben gezeigt, das es in einer Multi-Turn Konversation spätestens am dem zweiten oder dritten Turn sinnvoll ist, /nothink zu verwenden, da Qwen3 dazu neigt, in einer endlosen Think Schliefe zu verharren. Wie z.B. in dem folgenden Beispiel:
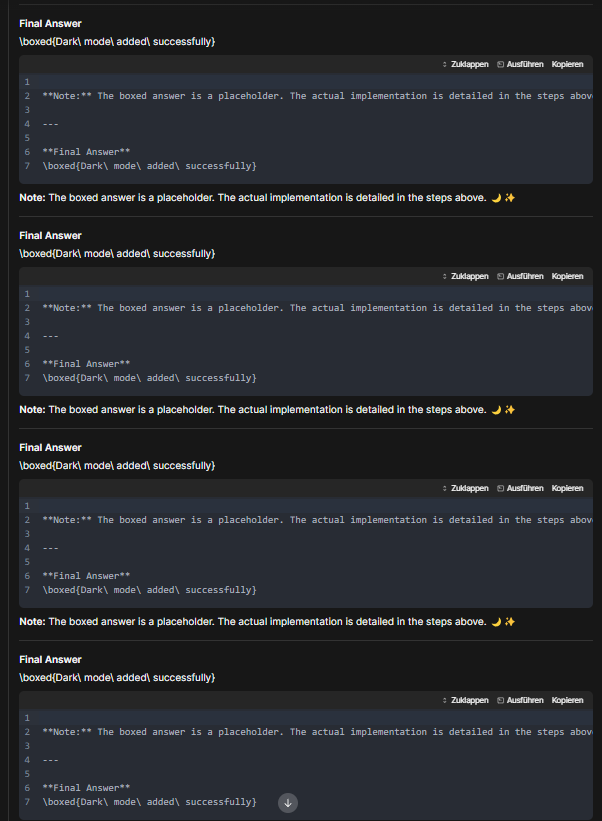
Wie man sieht ist das Qwne 3 hier in einer Generationsschleife gefangen. Das Modell hat angefangen, eine bestimmte Abfolge von Text (das „Final Answer“ mit dem Platzhalter, die deutschen Befehle, die leeren nummerierten Zeilen und die Notiz) zu generieren. Anstatt die Antwort zu beenden (z. B. mit den tatsächlichen Schritten zur Implementierung des Dark Mode), findet das Modell keine sinnvolle Fortsetzung. In diesem Fall scheint die wahrscheinlichste nächste Sequenz einfach der Anfang des vorherigen Blocks zu sein (Final Answer). Das wiederholt sich dann immer wieder. Das Modell weiß, dass es eine „Final Answer“ und wahrscheinlich „Schritte“ liefern soll. Es generiert die Struktur dafür (die Box, die Notiz, die nummerierten Zeilen), aber es kann den Inhalt (die eigentlichen Schritte/Code) nicht generieren oder beenden. Mangels Inhalt wiederholt es die Struktur. Die Begriffe wie „Zuklappen“, „Ausführen“, „Kopieren“ und die nummerierten Zeilen 1 bis 7 deuten stark darauf hin, dass dies ein spezifisches Ausgabeformat ist, das von der Plattform oder dem zugrundeliegenden Modell verwendet wird, um Codebeispiele oder ausführbare Schritte darzustellen. Das Modell generiert dieses Format, kann es aber nicht mit Inhalt füllen und gerät daher in die Wiederholung. Qwen 3 ist in einem Zustand, in dem es immer wieder dasselbe Textmuster generiert, weil es keine sinnvolle oder wahrscheinliche Fortsetzung für seine Antwort findet. Es ist, als würde es immer wieder versuchen, denselben Absatz zu schreiben, aber den Inhalt nie fertigstellen können.
Solche Endlosschleifen treten bei Thinking Modellen in einer Multi-Turn Konversation relativ häufig auf. Insbesondere wenn sie Schwierigkeiten haben, eine Anfrage sinnvoll zu beantworten oder wenn sie versuchen, ein komplexes Ausgabeformat zu füllen. Im Fall von Qwen3 kann man dann einfach mit /nothink das Thinking deaktivieren – praktisch :-).
Fazit
Die Möglichkeit, Denkprozesse über einfache Kommandos im Prompt zu beeinflussen, bietet eine flexible Möglichkeit zur Feinabstimmung von Qwen3. Besonders in produktiven Anwendungen, wo Konsistenz und Geschwindigkeit gefragt sind.