
Über das Experiment
Bei diesem Experiment verwende ich ChatGPT um einen Artikel über Elasticsearch zu schreiben. Keiner der Sätze ist von mir. Alles ist nahezu komplett generiert. Ich übernehme keine Garantie dafür, dass alles korrekt ist, obwohl alles was ich so gesehen habe sehr gut aussieht und ich auf den ersten Blick keine Fehler entdeckt habe.
Wozu habe ich das getan?
Naja, erst mal wollte ich natürlich mehr über ChatGPT erfahren, indem ich mich mehr damit befasse. Es stellen sich ja auch einige Fragen. Z.B.
- Wie geht man am besten vor, wenn man einen Text zu einem Thema erstellen möchte?
- Wie viel muss man noch nacharbeiten?
- (Wie gut) werden KI generierte Texte in den Google Index aufgenommen?
- Kann man die Texte einfach so verwenden?
- Wo sind die Grenzen?
- Wie erhält man gute Ergebnisse?
- etc.
Was habe ich getan, um den Text zu erstellen?
- Als erstes Mal habe ich unter https://openai.com/terms/ ob der Content, den ChatGPT so ausspuckt verwendet werden darf. Abschnitt 3.a gibt die Antwort darauf
- Ich habe der ChatGPT KI Fragen gestellt. Erst allgemein und dann immer spezifischer.
- Die Antworten habe ich dann hier auf der Seite zusammengetragen und Überschriften ergänzt
- Ich habe doppelte Aussagen entfernt, da Sätze bzw. komplette Abschnitte gerne mal wiederholt werden.
- Ich habe Abgeschnittene Sätze ergänzt, da es gelegentlich vorkommt, dass ChatGPT einfach mal mitten im Satz aufhört.
- Die Rechtschreibung- und Grammatikprüfung „Microsoft Editor“ hat hier und da noch ein Komma ergänzt.
- Einige exemplarische „Schnipsel“ habe ich mal bei Google in das Suchfeld eingetragen um zu prüfen, ob ChatGPT einfach nur irgendwo abschreibt 🙂 – aber keiner der von mir getesteten „Schnipsel“ konnte ich bei Google finden.
- Für den Beitrag habe ich mit Hilfe von Stable Diffusion noch ein Beitragsbild generiert (Mit Stable Diffusion erstellte Bilder fallen ausdrücklich unter CC0 1.0 Universal Public Domain 🙂 )
Das ganze Experiment sollte nicht länger als 30 Minuten dauern. Also mal sehen, was ich so in der Zeit schaffe …..
Disclaimer: Diesen Text hat eine KI (mit meiner Unterstützung) geschrieben.
Elasticsearch
Elasticsearch ist eine Suchmaschine, die auf der Java-basierten Apache Lucene-Bibliothek aufbaut. Es wird häufig für die Verarbeitung von großen Datenmengen und für die schnelle Suche innerhalb von Dokumenten verwendet. Eines der besonderen Merkmale von Elasticsearch ist, dass es in der Lage ist, nicht nur nach exakten Übereinstimmungen von Schlüsselwörtern zu suchen, sondern auch nach semantisch ähnlichen Begriffen und sogar nach falsch geschriebenen Wörtern.
Elasticsearch kann als Standalone-Anwendung oder als Teil einer größeren Anwendung verwendet werden. Es ist in der Lage, Daten aus verschiedenen Quellen zu indexieren, wie zum Beispiel Dokumenten, Websites und Anwendungslogs. Die Indexierung ermöglicht es, schnell auf die Daten zuzugreifen und sie zu durchsuchen, wodurch sich Elasticsearch besonders für die Verarbeitung von großen Datenmengen eignet.
Elasticsearch bietet auch eine Vielzahl von Möglichkeiten zur Anpassung der Suchergebnisse. So können beispielsweise bestimmte Filter angewendet werden, um das Suchergebnis einzugrenzen oder bestimmte Felder priorisiert anzuzeigen. Auch die Möglichkeit, Ergebnisse nach Relevanz oder nach einem bestimmten Attribut zu sortieren, steht zur Verfügung.
Eine weitere Stärke von Elasticsearch ist die Skalierbarkeit. Es kann problemlos auf mehrere Server verteilt werden, um die Leistung zu verbessern und die Verfügbarkeit zu erhöhen. Dies macht es zu einer beliebten Wahl für Unternehmen mit großen Datenmengen und hohem Traffic.
Insgesamt ist Elasticsearch eine leistungsstarke Suchmaschine, die sich besonders für die Verarbeitung von großen Datenmengen und die schnelle Suche innerhalb von Dokumenten eignet. Es bietet zahlreiche Möglichkeiten zur Anpassung der Suchergebnisse und ist skalierbar, wodurch es sich für Unternehmen mit hohem Traffic eignet.
Große Datenmengen in Elasticsearch
Die Verarbeitung von großen Datenmengen ist eines der wichtigsten Einsatzgebiete von Elasticsearch. Das System ist in der Lage, Daten aus verschiedenen Quellen zu indexieren, wodurch sie schnell und einfach durchsucht werden können. Durch die Indexierung werden die Daten in einer strukturierten Form gespeichert, die für die Suche optimiert ist.
Elasticsearch kann Daten aus verschiedenen Quellen indexieren, wie zum Beispiel:
- Dokumente: Elasticsearch kann verschiedene Arten von Dokumenten wie Word-Dateien, PDF-Dateien und andere Office-Dokumente indexieren.
- Websites: Elasticsearch kann auch Websites indexieren und die Inhalte für die Suche verfügbar machen.
- Anwendungslogs: Elasticsearch kann auch Anwendungslogs indexieren und durchsuchen. Dies ist besonders nützlich, um Fehler in Anwendungen zu diagnostizieren und zu beheben.
- Datenbanken: Elasticsearch kann auch mit verschiedenen Arten von Datenbanken integriert werden, um die Daten zu indexieren und zu durchsuchen.
- Social Media-Plattformen: Elasticsearch kann auch Daten von Social Media-Plattformen wie Twitter oder Facebook indexieren und für die Suche verfügbar machen.
Insgesamt kann Elasticsearch Daten aus einer Vielzahl von Quellen indexieren und durchsuchen, um schnell und einfach relevante Ergebnisse zu liefern.
Der Elasticsearch-Index ist eine strukturierte Sammlung von Daten, die für die Suche optimiert ist. Er dient als eine Art Datenbank für die gespeicherten Daten und ermöglicht es, schnell auf sie zuzugreifen und sie zu durchsuchen.
Der Elasticsearch-Index besteht aus Dokumenten, die aus verschiedenen Feldern bestehen. Jedes Dokument ist eine Sammlung von Key-Value-Paaren, wobei jedes Feld einem bestimmten Key zugeordnet ist. Beim Indexieren von Daten werden die Dokumente in den Index aufgenommen und entsprechend ihrer Felder strukturiert.
Die Indexierung von Daten in Elasticsearch erfolgt in der Regel in Echtzeit, was bedeutet, dass die Daten sofort nach dem Hinzufügen zur Suche verfügbar sind. Es ist auch möglich, die Indexierung von Daten zeitverzögert durchzuführen, um die Leistung zu verbessern.
Der Elasticsearch-Index kann auch repliziert werden, um die Verfügbarkeit und die Leistung zu verbessern. Durch die Replikation werden Kopien des Index auf mehrere Server verteilt, wodurch die Last auf mehrere Maschinen verteilt wird, und die Verfügbarkeit erhöht wird.
Insgesamt ist der Elasticsearch-Index ein wichtiger Bestandteil des Systems und ermöglicht es, schnell und einfach auf strukturierte Daten zuzugreifen und sie zu durchsuchen.
Elasticsearch Integration
Elasticsearch kann in vorhandene Anwendungen auf verschiedene Arten integriert werden. Eine Möglichkeit ist die Verwendung von Elasticsearch als Standalone-Anwendung und die Integration über das Elasticsearch-API. Dies ermöglicht es, Elasticsearch-Funktionen wie das Indexieren und Durchsuchen von Daten direkt in die Anwendung zu integrieren.
Eine weitere Möglichkeit ist die Verwendung von Elasticsearch als Suchmaschine für eine Web-Anwendung. Dies kann beispielsweise über eine Schnittstelle wie ein Web-Formular erfolgen, über das Benutzer nach bestimmten Begriffen suchen können. Die Ergebnisse werden dann von Elasticsearch geliefert und in der Anwendung angezeigt.
Es gibt auch Plugins und Module für verschiedene Entwicklungsumgebungen und Frameworks, die die Integration von Elasticsearch erleichtern. Beispiele hierfür sind das Elasticsearch-Modul für Python oder das Elasticsearch-Plugin für Drupal.
Insgesamt gibt es viele Möglichkeiten, wie Elasticsearch in vorhandene Anwendungen integriert werden kann. Welche Methode am besten geeignet ist, hängt von den Anforderungen der Anwendung und den Vorlieben des Entwicklers ab.
Eine Möglichkeit ist die Verwendung von Elasticsearch als Standalone-Anwendung und die Integration über die Elasticsearch-API.
- Standalone-Anwendung: Elasticsearch kann als eigenständige Anwendung installiert und betrieben werden. Die Anwendung kann dann über die Elasticsearch-API aufgerufen werden, um Indexierungs- und Suchvorgänge durchzuführen.
- Integration über die Elasticsearch-API: Elasticsearch bietet eine REST-API, die es ermöglicht, Indexierungs- und Suchvorgänge über HTTP-Anfragen durchzuführen. Die API kann von jeder Anwendung aufgerufen werden, die über eine HTTP-Verbindung verfügt, um Elasticsearch-Funktionalitäten zu nutzen.
- Verwendung von Clients: Es gibt auch eine Vielzahl von Clients, die es ermöglichen, Elasticsearch von verschiedenen Programmiersprachen aus zu nutzen. Diese Clients stellen die Verbindung zu Elasticsearch her und bieten eine einfache Möglichkeit, die API aufzurufen und Indexierungs- und Suchvorgänge durchzuführen.
Elasticsearch bietet Unterstützung für verschiedene Programmiersprachen, darunter:
Python: Es gibt eine offizielle Python-Bibliothek namens „elasticsearch-py“ für den Zugriff auf Elasticsearch-Server von Python-Anwendungen.- Ruby: Es gibt eine offizielle Ruby-Bibliothek namens „elasticsearch-ruby“ für den Zugriff auf Elasticsearch-Server von Ruby-Anwendungen.
- PHP: Es gibt eine offizielle PHP-Bibliothek namens „elasticsearch-php“ für den Zugriff auf Elasticsearch-Server von PHP-Anwendungen.
- Perl: Es gibt eine offizielle Perl-Bibliothek namens „Elasticsearch“ für den Zugriff auf Elasticsearch-Server von Perl-Anwendungen.
- .NET: Es gibt eine offizielle .NET-Bibliothek namens „Elasticsearch.Net“ für den Zugriff auf Elasticsearch-Server von .NET-Anwendungen.
- Node.js: Es gibt eine offizielle Node.js-Bibliothek namens „elasticsearch“ für den Zugriff auf Elasticsearch-Server von Node.js-Anwendungen.
Es gibt auch andere Bibliotheken und Treiber für andere Sprachen, die von der Elasticsearch-Community entwickelt wurden, z.B. für Go und Scala.
Anpassung der Suchergebnisse
In Elasticsearch gibt es verschiedene Möglichkeiten, die Suchergebnisse anzupassen und zu optimieren. Einige Beispiele sind:
- Filtern: Es ist möglich, bestimmte Filter anzuwenden, um das Suchergebnis einzugrenzen. Dies kann zum Beispiel durchgeführt werden, indem bestimmte Felder oder Werte ausgeschlossen werden.
- Anpassen von Treffern: Es ist auch möglich, das Suchergebnis anzupassen, indem bestimmte Felder priorisiert angezeigt werden oder indem das Suchergebnis in einer bestimmten Reihenfolge sortiert wird.
- Nutzung von Aggregationen: Aggregationen ermöglichen es, das Suchergebnis zu gruppieren und zusammenzufassen, um bestimmte Trends oder Muster zu identifizieren.
- Nutzung von Anfrage- und Filterexpressionen: Es ist auch möglich, komplexe Anfragen und Filterexpressionen zu verwenden, um das Suchergebnis anzupassen. Dies kann zum Beispiel durchgeführt werden, indem bestimmte Wörter oder Wortgruppen gewichtet werden oder indem bestimmte Suchlogiken angewendet werden.
Insgesamt gibt es viele Möglichkeiten, das Suchergebnis in Elasticsearch anzupassen und zu optimieren, um relevante Ergebnisse zu liefern. Durch die Verwendung von Filtern, Anpassung von Treffern, Aggregationen und Anfrage- und Filterexpressionen können die Suchergebnisse auf die Bedürfnisse und Anforderungen angepasst werden.
Elasticsearch auf mehrere Server verteilen
Es gibt verschiedene Möglichkeiten, Elasticsearch auf mehrere Server zu verteilen:
- Verwendung von Elasticsearch-Clustern: Elasticsearch bietet die Möglichkeit, mehrere Server in einem Cluster zusammenzufassen. Jeder Server im Cluster wird als Knoten bezeichnet und kann Indexierungs- und Suchvorgänge durchführen. Die Knoten im Cluster arbeiten zusammen, um die Verfügbarkeit und Leistung zu verbessern.
- Verwendung von Replikation: Elasticsearch bietet auch die Möglichkeit, Indexe zu replizieren, um die Verfügbarkeit und Leistung zu verbessern. Durch die Replikation werden Kopien des Index auf mehrere Server verteilt, wodurch die Last auf mehrere Maschinen verteilt wird und die Verfügbarkeit erhöht wird.
- Verwendung von Sharding: Elasticsearch bietet auch die Möglichkeit, Indexe zu „sharden“, um die Leistung zu verbessern. Durch das Sharding werden die Indexe auf mehrere Server aufgeteilt, wodurch die Last auf mehrere Maschinen verteilt wird und die Leistung erhöht wird.
Insgesamt gibt es verschiedene Möglichkeiten, Elasticsearch auf mehrere Server zu verteilen, um die Verfügbarkeit und Leistung zu verbessern. Durch die Verwendung von Clustern, Replikation und Sharding kann Elasticsearch auf mehrere Server verteilt werden, um die Leistung und Verfügbarkeit zu optimieren.
Loging in Elasticsearch
Elasticsearch kann auch für das Logging verwendet werden. Elasticsearch ist eine plattformunabhängige Suchmaschine, die für die Verarbeitung und Analyse von großen Datenmengen in Echtzeit ausgelegt ist. Dies macht es zu einer geeigneten Wahl für das Logging, da es möglich ist, große Mengen von Logdaten schnell und effizient zu verarbeiten und zu analysieren.
Es gibt verschiedene Möglichkeiten, wie Elasticsearch für das Logging verwendet werden kann:
- Verwendung von Logstash: Logstash ist ein Open-Source-Datenverarbeitungstool, das es ermöglicht, Logdaten von verschiedenen Quellen zu sammeln und an Elasticsearch zu senden. Logstash bietet zahlreiche Möglichkeiten zur Verarbeitung und Anpassung von Logdaten, bevor sie an Elasticsearch gesendet werden.
- Verwendung von Beats: Beats ist eine Familie von Open-Source-Datensammlertools, die es ermöglichen, Logdaten von verschiedenen Quellen zu sammeln und an Elasticsearch zu senden. Jeder Beat ist auf die Sammlung von Logdaten von einer bestimmten Quelle spezialisiert und bietet Möglichkeiten zur Verarbeitung und Anpassung von Logdaten, bevor sie an Elasticsearch gesendet werden.
- Direkte Integration: Elasticsearch bietet auch eine REST-API, die es ermöglicht, Logdaten direkt an Elasticsearch zu senden. Dies bietet die Möglichkeit, Elasticsearch in bestehende Anwendungen zu integrieren und Logdaten direkt an Elasticsearch zu senden
Elasticsearch Daten visualisieren
Es gibt verschiedene Möglichkeiten, um Daten aus Elasticsearch zu visualisieren:
- Verwenden Sie das integrierte Dashboard von Elasticsearch: Elasticsearch bietet ein integriertes Dashboard, das verschiedene Arten von Diagrammen und Metriken visualisieren kann. Sie können das Dashboard verwenden, um eine Vielzahl von Daten aus Elasticsearch zu visualisieren, z.B. Anzahl der Dokumente in einem Index, Anzahl der Anfragen pro Sekunde, Durchschnittliche Antwortzeit usw.
- Verwenden Sie ein externes Dashboard-Tool: Es gibt viele externe Dashboard-Tools, die Sie verwenden können, um Daten aus Elasticsearch zu visualisieren. Zum Beispiel können Sie Grafana verwenden, um interaktive Diagramme und Metriken von Elasticsearch-Daten zu erstellen. Andere Optionen sind Kibana (von Elastic), Tableau und PowerBI.
- Verwenden Sie eine Programmiersprache oder ein Framework: Sie können auch eine Programmiersprache oder ein Framework verwenden, um Elasticsearch-Daten zu visualisieren. Zum Beispiel können Sie Python mit Bibliotheken wie Matplotlib oder Seaborn verwenden, um Diagramme von Elasticsearch-Daten zu erstellen. Oder Sie können JavaScript-Frameworks wie D3.js oder Highcharts verwenden, um interaktive Diagramme zu erstellen.
Es ist wichtig zu beachten, dass Sie möglicherweise einige Vorarbeit leisten müssen, um die Daten aus Elasticsearch in eine Form zu bringen, die von den oben genannten Tools oder Frameworks verarbeitet werden kann. Sie können zum Beispiel Elasticsearch-Abfragen verwenden, um die Daten abzurufen und gegebenenfalls aggregieren oder transformieren, bevor Sie sie visualisieren.
Die Auswahl der richtigen Methode hängt von verschiedenen Faktoren ab, wie den Anforderungen an die Visualisierung, der verfügbaren Ressourcen und den Vorlieben der Person, die die Visualisierung erstellt.
Einige Dinge, die bei der Auswahl der richtigen Methode berücksichtigt werden sollten, sind:
- Die Art der Daten: Wenn die Daten sehr strukturiert sind und eine klare Hierarchie aufweisen, eignen sich möglicherweise Diagrammtypen wie Balkendiagramme oder Liniendiagramme besser als andere. Wenn die Daten weniger strukturiert sind, könnten andere Diagrammtypen wie Kreisdiagramme oder Netzdiagramme besser geeignet sein.
- Die Zielgruppe der Visualisierung: Überlegen Sie, für wen die Visualisierung bestimmt ist und was diese Personen von der Visualisierung erwarten. Zum Beispiel könnten technisch versierte Benutzer eher interaktive Diagramme mit Drill-down-Funktionen bevorzugen, während weniger technikaffine Benutzer einfache, leicht verständliche Diagramme bevorzugen.
- Die verfügbaren Ressourcen: Berücksichtigen Sie, wie viel Zeit und Mühe Sie in die Erstellung der Visualisierung investieren möchten und welche Tools und Technologien zur Verfügung stehen. Wenn Sie zum Beispiel keine Erfahrung mit Programmiersprachen haben, könnte es schwierig sein, eine Visualisierung mit einer Programmiersprache oder einem Framework zu erstellen. In diesem Fall wäre es möglicherweise einfacher, ein externes Dashboard-Tool wie Grafana oder Kibana zu verwenden.
Es lohnt sich auch, verschiedene Methoden auszuprobieren und zu vergleichen, um herauszufinden, welche am besten zu Ihren Anforderungen passt.
Elasticsearch Alternativen
Ja, es gibt eine Reihe von Alternativen zu Elasticsearch, die für verschiedene Anwendungsfälle geeignet sind. Einige Beispiele für Alternativen zu Elasticsearch sind:
- Apache Solr: Solr ist eine freie Suchmaschine, die von der Apache Software Foundation entwickelt wurde und auf der Lucene-Bibliothek basiert. Solr ist eine gute Option für Unternehmen, die eine leistungsstarke und skalierbare Suchlösung suchen.
- Apache Lucene: Lucene ist eine freie Suchbibliothek, die von der Apache Software Foundation entwickelt wurde. Es kann als Standalone-Suchmaschine verwendet werden, aber es ist in der Regel als Kernkomponente von anderen Suchmaschinen wie Solr oder Elasticsearch zu finden.
- MongoDB: MongoDB ist eine NoSQL-Datenbank, die für die Verwendung mit Dokumentenstrukturen optimiert ist. Es ist eine gute Option für Unternehmen, die eine flexibele und skalierbare Datenbanklösung suchen, die sich leicht anpassen lässt.
- Apache Cassandra: Cassandra ist eine freie NoSQL-Datenbank, die von der Apache Software Foundation entwickelt wurde. Es ist besonders für die Verwendung in verteilten Systemen geeignet und bietet hohe Verfügbarkeit und Skalierbarkeit.
Es lohnt sich, verschiedene Alternativen zu vergleichen und zu prüfen, welche am besten zu den Anforderungen und Bedürfnissen Ihres Unternehmens passt. Es gibt keine „eine Größe passt für alle“ -Lösung, und die Wahl der richtigen Plattform hängt von vielen Faktoren ab.
Lucene
Apache Lucene ist eine Java-basierte Bibliothek zur Indizierung und Suche von Dokumenten. Es wurde ursprünglich von Doug Cutting entwickelt und ist mittlerweile ein wichtiger Bestandteil vieler Suchmaschinen und Anwendungen, die auf der Suche und Verarbeitung von großen Datenmengen basieren.
Lucene bietet eine Vielzahl von Funktionen zur Indizierung und Suche von Dokumenten, wie zum Beispiel:
- Volltextsuche: Lucene ermöglicht es, nach exakten Übereinstimmungen von Schlüsselwörtern in Dokumenten zu suchen.
- Fuzzy Search: Lucene bietet auch die Möglichkeit, nach semantisch ähnlichen Begriffen oder falsch geschriebenen Wörtern zu suchen.
- Suchranking: Lucene bietet auch Funktionen zur Berechnung der Relevanz von Suchergebnissen, um die wichtigsten Ergebnisse anzuzeigen.
- Indizierung: Lucene bietet auch Funktionen zur Indizierung von Dokumenten, um sie schnell und einfach durchsuchen zu können.
Lucene ist eine leistungsstarke Bibliothek, die häufig in Suchmaschinen und Anwendungen verwendet wird, die auf der Verarbeitung von großen Datenmengen basieren. Es bietet zahlreiche Funktionen zur Indizierung und Suche von Dokumenten und ist in der Lage, schnell und präzise Ergebnisse zu liefern.
Der invertierte Index
Ein invertierter Index ist eine spezielle Art von Index, der für die schnelle Suche innerhalb von Dokumenten verwendet wird. Er wird häufig in Suchmaschinen verwendet, um die Leistung zu verbessern und schnell relevante Ergebnisse liefern zu können.
Ein invertierter Index besteht aus einer Liste von Wörtern, die in den Dokumenten enthalten sind, und den Dokumenten, in denen diese Wörter vorkommen. Jedes Wort wird mit einer Liste von Dokumenten verknüpft, in denen es vorkommt. Der Index wird „invertiert“, weil er das Verhältnis von Wörtern zu Dokumenten umkehrt, anstatt Dokumente nach Wörtern zu gruppieren.
Ein invertierter Index ermöglicht es, schnell nach bestimmten Wörtern in Dokumenten zu suchen, indem man einfach die Liste der Dokumente abruft, in denen das Wort vorkommt. Dies ist deutlich schneller als eine Suche in den Dokumenten selbst, da der Index bereits strukturiert und optimiert für die Suche ist.
Invertierte Indizes werden häufig in Suchmaschinen und anderen Anwendungen verwendet, die auf der Verarbeitung von großen Datenmengen basieren. Sie ermöglichen es, schnell relevante Ergebnisse zu liefern und die Leistung zu verbessern.
Ein invertierter Index wird von vielen verschiedenen Datenbanken und Suchmaschinen verwendet. Einige Beispiele für Datenbanken und Suchmaschinen, die den invertierten Index verwenden, sind:
- Elasticsearch: Elasticsearch ist eine freie Such- und Analyseplattform, die auf dem invertierten Index basiert.
- Apache Solr: Solr ist eine freie Suchmaschine, die auf der Lucene-Bibliothek basiert und den invertierten Index verwendet.
- Apache Lucene: Lucene ist eine freie Suchbibliothek, die von der Apache Software Foundation entwickelt wurde und den invertierten Index verwendet. Es kann als Standalone-Suchmaschine verwendet werden, aber es ist in der Regel als Kernkomponente von anderen Suchmaschinen wie Solr oder Elasticsearch zu finden.
- Google Search: Google Search, die Suchmaschine von Google, verwendet den invertierten Index, um Webseiten und andere Dokumente zu indizieren und zu suchen.
- Microsoft Bing: Bing, die Suchmaschine von Microsoft, verwendet den invertierten Index, um Webseiten und andere Dokumente zu indizieren und zu suchen.
Einige relationale Datenbanken bieten auch eigene freie Textsuche-Funktionen, die ähnlich wie der invertierte Index funktionieren, aber die Details der Implementierung können unterschiedlich sein. Zum Beispiel bietet MySQL seit Version 5.6 die Möglichkeit, FULLTEXT-Indizes zu erstellen, die für die freie Textsuche verwendet werden können. In Oracle gibt es die Möglichkeit, CONTAINS-Suchabfragen zu verwenden, um Daten in indizierten Sichten oder Tabellen zu durchsuchen.
Die FTS3 (Full-Text Search Version 3) und FTS4 (Full-Text Search Version 4) Extensions in SQLite sind Erweiterungen, die es ermöglichen, freie Textsuche in SQLite-Datenbanken durchzuführen. Mit diesen Erweiterungen können Sie Abfragen verwenden, um nach Wörtern oder Phrasen in indizierten Textspalten zu suchen.
FTS3 wurde in SQLite Version 3.4.0 eingeführt und bot grundlegende Funktionen wie die Möglichkeit, Wörter und Phrasen zu suchen, Schreibweisen zu ignorieren und Ergebnisse zu sortieren. FTS4 wurde in SQLite Version 3.7.4 eingeführt und bietet verbesserte Funktionen wie die Möglichkeit, Dokumentgewichtungen anzugeben und die Relevanz von Suchergebnissen zu berechnen.
Die FTS3 und FTS4 Extensions in SQLite können verwendet werden, um die Suche in Textspalten von Datenbanktabellen zu beschleunigen und zu verbessern. Sie eignen sich besonders für Anwendungen, die eine schnelle und leistungsstarke freie Textsuche benötigen, z.B. in Suchmaschinen, Blogs oder anderen Web-Anwendungen. Es ist wichtig zu beachten, dass die FTS3 und FTS4 Extensions in SQLite nur für die Suche in Textspalten verwendet werden können und nicht für die Suche in anderen Datentypen wie Zahlen oder Datumswerte.
Der invertierte Index in Apache Lucene
In Apache Lucene wird der invertierte Index verwendet, um schnell und effektiv nach bestimmten Wörtern in Dokumenten zu suchen. Lucene baut auf dem Konzept des invertierten Indexes auf und implementiert es in Form eines speziellen Datenstruktur, die als „Segment“ bezeichnet wird.
Ein Segment in Lucene ist eine strukturierte Sammlung von Dokumenten, die für die Suche optimiert sind. Jedes Dokument wird in einzelne Tokens unterteilt, die dann in den invertierten Index aufgenommen werden. Jedes Token wird mit einer Liste von Dokumenten verknüpft, in denen es vorkommt, wodurch schnell relevante Ergebnisse geliefert werden können.
Der invertierte Index in Lucene wird verwendet, um schnell nach exakten Übereinstimmungen von Schlüsselwörtern in Dokumenten zu suchen. Es ist auch möglich, nach semantisch ähnlichen Begriffen oder falsch geschriebenen Wörtern zu suchen, indem man entsprechende Suchalgorithmen verwendet.
Der invertierte Index in Lucene wird auch verwendet, um die Relevanz von Suchergebnissen zu berechnen. Dies geschieht, indem bestimmte Faktoren wie die Häufigkeit, in der ein Wort in einem Dokument vorkommt, berücksichtigt werden. Auf diese Weise können die wichtigsten Ergebnisse angezeigt werden.
Insgesamt ist der invertierte Index in Lucene ein wichtiger Bestandteil des Systems und ermöglicht es, schnell und effektiv nach bestimmten Wörtern in Dokumenten zu suchen und relevante Ergebnisse zu liefern.
Term Frequenz in Lucene
In Apache Lucene wird die Termfrequenz (TF) verwendet, um die Häufigkeit eines bestimmten Terms in einem Dokument zu berechnen. Die Termfrequenz gibt an, wie oft ein bestimmtes Wort in einem Dokument vorkommt und wird häufig verwendet, um die Relevanz von Suchergebnissen zu berechnen.
Die Termfrequenz wird häufig in Verbindung mit der inverse Dokumentfrequenz (IDF) verwendet, um die Relevanz von Suchergebnissen zu berechnen. Die inverse Dokumentfrequenz gibt an, wie häufig ein bestimmtes Wort in allen Dokumenten vorkommt. Die Kombination von Termfrequenz und inverse Dokumentfrequenz wird als Termfrequenz-inverse Dokumentfrequenz (TF-IDF) bezeichnet und wird häufig verwendet, um die Relevanz von Suchergebnissen zu berechnen.
Die Termfrequenz wird in Lucene berechnet, indem zunächst das Dokument in einzelne Tokens unterteilt wird. Jedes Token wird dann gezählt und die Häufigkeit des Tokens im Dokument berechnet. Die Termfrequenz wird dann als Anzahl der Tokens im Dokument dividiert durch die Gesamtzahl der Tokens im Dokument berechnet.
Die Termfrequenz in Lucene ist ein wichtiger Faktor bei der Berechnung der Relevanz von Suchergebnissen und wird verwendet, um sicherzustellen, dass wichtige und relevante Ergebnisse angezeigt werden.
Berechnung der Termfrequenz-inverse Dokumentfrequenz
Die Termfrequenz-inverse Dokumentfrequenz (TF-IDF) ist ein Maß dafür, wie relevant ein bestimmtes Wort in einem Dokument im Vergleich zu anderen Dokumenten ist. Sie wird häufig in Suchmaschinen und anderen Anwendungen verwendet, die auf der Verarbeitung von großen Datenmengen basieren, um die Relevanz von Suchergebnissen zu berechnen.
Die TF-IDF wird berechnet, indem zunächst die Termfrequenz (TF) und die inverse Dokumentfrequenz (IDF) berechnet werden. Die Termfrequenz gibt an, wie oft ein bestimmtes Wort in einem Dokument vorkommt, während die inverse Dokumentfrequenz angibt, wie häufig das Wort in allen Dokumenten vorkommt.
Die TF-IDF wird dann berechnet, indem die Termfrequenz mit der inverse Dokumentfrequenz multipliziert wird. Die Formel zur Berechnung der TF-IDF lautet:
TF-IDF = TF * IDF
Die TF-IDF wird häufig verwendet, um die Relevanz von Suchergebnissen zu berechnen. Dokumente mit einer höheren TF-IDF werden als relevanter angesehen und werden daher in der Regel in den Suchergebnissen weiter oben angezeigt.
Die Termfrequenz wird berechnet, indem zunächst das Dokument in einzelne Tokens unterteilt wird. Jedes Token wird dann gezählt und die Häufigkeit des Tokens im Dokument berechnet. Die Termfrequenz wird dann als Anzahl der Tokens im Dokument dividiert durch die Gesamtzahl der Tokens im Dokument berechnet. Die Formel zur Berechnung der Termfrequenz lautet:
TF = Anzahl der Tokens des bestimmten Worts / Gesamtzahl der Tokens im Dokument
Die inverse Dokumentfrequenz (IDF) ist ein Maß dafür, wie häufig ein bestimmtes Wort in allen Dokumenten vorkommt. Sie wird häufig in Suchmaschinen und anderen Anwendungen verwendet, die auf der Verarbeitung von großen Datenmengen basieren, um die Relevanz von Suchergebnissen zu berechnen.
Die inverse Dokumentfrequenz wird berechnet, indem zunächst die Anzahl der Dokumente berechnet wird, in denen das bestimmte Wort vorkommt. Diese Anzahl wird dann durch die Gesamtzahl der Dokumente dividiert und das Ergebnis wird mit dem natürlichen Logarithmus der Gesamtzahl der Dokumente multipliziert. Die Formel zur Berechnung der inverse Dokumentfrequenz lautet:
IDF = Log(Gesamtzahl der Dokumente / Anzahl der Dokumente mit dem bestimmten Wort)
Ende des Experiments
Nach weniger als einer halben Stunde habe ich den Text zusammenkopiert und grob strukturiert. Die Informationen sind größtenteils nützlich und für jemanden, der sich noch nie mit Elasticsearch beschäftigt hat auch relevant. Die Nutzung des ChatGPT Interface ist denkbar einfach.
Frage/Thema eintippen (sogar auf Deutsch) und die Antwort abwarten. Gelegentlich hilft es auf „Regenerate response“ zu klicken. Z.B. wenn ChatGPT mitten im Satz abbricht.
Wichtig ist es, zu wissen worüber man schreiben möchte (sofern man das noch Schreiben nennen kann), um die richtigen Fragen stellen zu können. So wusste ich z.B. dass in Elasticsearch Begriffe wie Termfrequenz und Dokumentfrequenz eine Rolle spielen, so dass ich konkret danach Fragen konnte.
Sehr interessant finde ich, dass keiner der von mir in Google eingegebenen „Schnipsel“ ein Suchergebnis geliefert hat. Ich einige Schnipsel aus je 6-8 Wörtern aus den generierten Texten kopiert und mal bei Google danach gesucht. Keiner der von mir getesteten Schnipsel hat ein Suchergebnis geliefert.
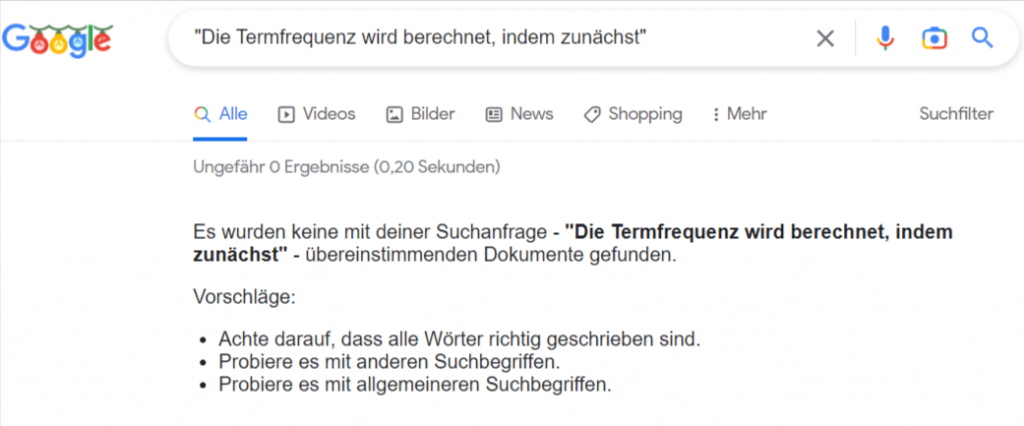
Das ist ein sehr gutes Zeichen, dass darauf hindeutet, dass die Texte tatsächlich nicht einfach aus dem Internet kopiert werden und stattdessen von der KI selbst erstellt werden.
Ein wenig überrascht bin ich darüber, dass man in der deutschen SEO-Welt bisher noch so wenig darüber liest. So gibt es bisher keinen einzigen Beitrag über das Generieren von Texten im ABAKUS Internet Marketing Forum während unter https://www.webmasterworld.com/ und https://www.blackhatworld.com/ schon heftige Debatten über ChatGPT laufen.
Naja, alles in Allem ein Test, der bisher sehr erfolgreich verlaufen ist, bleibt nur abzuwarten, ob Google den Text als „Generiert“ erkennt und einfach nicht indiziert oder meine ganze Webseite aus dem Index verbannt …. Das Erkennen von Deep-Fakes ist ja auch relativ leicht möglich und rein technisch unterscheiden sich Deep-Fakes nicht so sehr von generierten Texten. In beiden Fällen werden Inhalte von Deep-Learning Modellen generiert. Details zu einem relativ aktuellen „End-to-End DeepFake Detection Framework“ kann man z.B. hier nachlesen.